“人工智能+”时代, 作为AI人工智能三大要素之一的“算力”成为各行业信息基础设施的重要部分。配置算力基础设施,为Gemma、LLaMA、DeepSeek等大模型的内部部署、模型训练和推理等AI应用和研究,提供一个高速、稳定、安全的AI环境,是当前各行业信息部门面临的任务。
一.算力基础设施类型
AI算力基础设施可以分为AI训练、AI推理、AI嵌入和AI桌面设施4类,如图1所示。

图1 AI算力设施类别
AI训练设施主要用于需要高算力的大模型部署(例如DeepSeek全量模型)、模型研发和训练以及大模型微调。AI推理设施用于中小规模模型部署(例如DeepSeek蒸馏模型)、模型的推理(即训练好的模型的应用),也可以用于模型的研发。AI推理设施要考虑支撑大量AI业务应用(例如临床辅助诊断、影像辅助诊断等),这些业务应用数量较多,但算力要求不高,为了充分利用算力资源而需要采用算力卡虚拟化或多实例技术,实现算力按需配置。AI嵌入设施主要用于嵌入式边缘计算场景,进行嵌入模型的训练和推理。AI桌面设施是指在现有桌面电脑上扩展AI算力,随着AI的广泛应用,个人设备将具备日益强大的AI功能,这就要求桌面计算机能提供充足的AI算力。
二.算力基础设施
1.AI服务器
AI服务器主要是为人工智能的机器学习提供计算能力支持。AI服务器的配置需要根据用户应用需求,选择合适的CPU、内存、硬盘(SSD或机械硬盘),以及提供AI算力的算力卡、算力卡内存。如果算力卡不支持显示器接口,还需要配置显卡。服务器的机箱尺寸、各类接口和卡槽,需要根据算力卡的尺寸、接口类型和张数设置。算力卡耗电较高,服务器电源功率必须充分满足算力卡的功耗与散热要求。除了硬件,AI服务器还需要安装操作系统以及AI架构件和工具包软件等。
2.AI算力卡
AI算力卡是算力服务器的核心部件, 能够处理大规模数据集和复杂的数学运算,适用于机器学习、深度学习、自然语言处理、计算机视觉等领域的应用,通过高性能计算设备,AI算力卡可以加速神经网络的训练过程,提高模型精度。
常用的AI算力卡有英伟达、英特尔、AMD等的图形处理单元(GPU),谷歌的张量处理单元(TPU),以及华为的神经网络处理单元(NPU)等。算力卡的主要性能指标包括计算精度、内核类型和内存容量,下面分别介绍。
1)主要性能指标
(1)计算精度与速度
常用的算力卡计算精度如表1所示。除了表中所列的精度指标,不同的算力卡厂家还会有其他的精度指标。
表1 算力卡计算精度
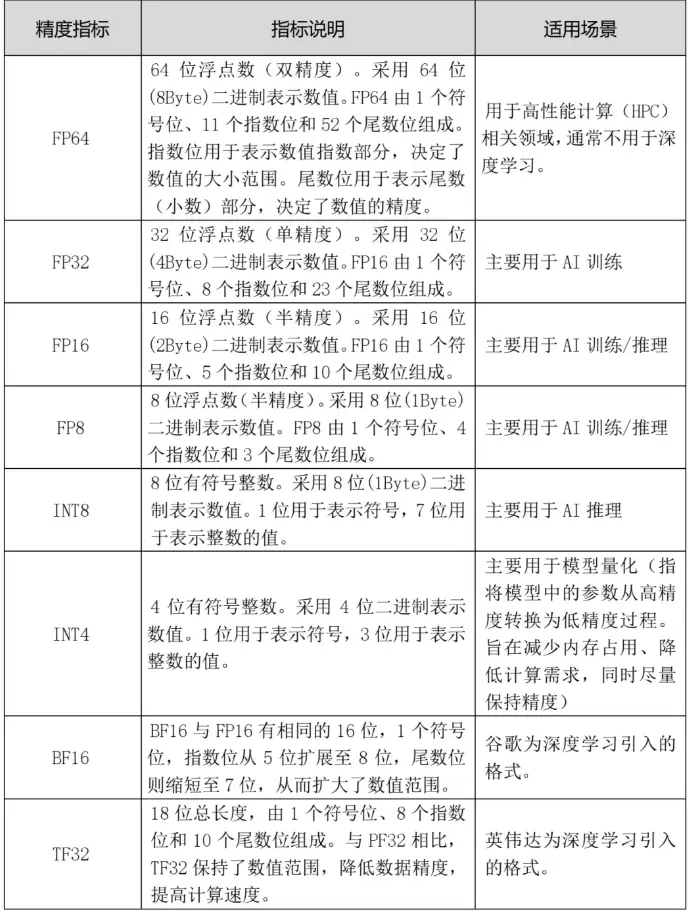
表2 算力卡的计算速度类型和单位。

算力卡的计算精度和运算速度的选择,需要按照算力卡的应用场景来确定。
(2)内核
算力卡芯片的内核用于数据计算,其核数量远远大于CPU,甚至高达上万个。英伟达GPU内核主要有CUDA核和Tensor核两类。
CUDA核主要用于执行加法、乘法运算通用计算任务:1)执行并行计算任务;2)支持大规模的浮点运算和整数运算,适用于图像和视频处理、科学计算以及实时物理计算等;3)多线程并行执行,能够一次性运行数千甚至数百万个线程(一个CUDA核可以并行处理多个线程)。
Tensor Core为加速深度学习中的张量运算设计:1)优化了矩阵乘法和累加运算,这些运算是深度学习的核心计算任务;2)在深度学习推理和训练方面表现出色,能够大幅提高计算性能,同时维持较低的精度损失。
(3)内存
算力卡的内存(常称为“显存”)是指算力卡专用的存储芯片,用于存储算力卡需要快速读写的数据信息,如模型参数、数据缓存等。显存的容量通常以GB(2³⁰)为单位,容量越大,算力卡能处理的数据规模就越大。
算力卡内存的容量需要根据模型的使用情况考虑,对于深度学习神经网络模型,算力卡内存容量可以按下列公式估算:
算力卡内存容量 =(1.2-1.4) X (训练模型参数量 X 计算精度的字节(Byte)数)系数(1.2-1.4)是在模型参数所需要内存的基础上,增加的额外开销,如数据缓存等。模型训练系数可选1.4,模型推理可选1.2。例如,用于推理的模型参数是70B(70X10⁹),计算精度FP16(2Byte),算力卡内存容量 = 1.2 X70X109 X2,结果是168,内存容量约为168GB。在配置算力卡内存时,还需要考虑模型用户并发数。在确定内存容量前,用户应向模型研发人员了解内存的实际需求。
采用量化技术,将模型参数的精度从浮点数降低到低位表示(如表1中INT8、INT4),可以显著降低内存和计算需求,使模型在资源有限的设备上更高效地部署。因为降低精度可能会影响输出的准确性,需要仔细管理以保持模型的性能。
显存的另一个指标是带宽,显存带宽决定了GPU从显存中读取或写入数据的速度。显存带宽越高,数据传输越快,算力卡的处理效率也越高。
(4)功耗
功耗是算力卡的重要指标,在算力卡规格书中通常以TDP(热设计功耗)、典型功耗或最大功耗等表示。算力卡的功耗和散热是AI服务器需要考虑的重要问题,在服务器的选型时需要充分考虑,并不是所有服务器都考虑了GPU的使用,特别是GPU模组的使用场景。
2)英伟达GPU
英伟达的图形处理单元GPU(Graphic Processing Unit)是目前应用最广泛的AI算力卡,早期的GPU主要用于计算机的显卡,为图形和视频渲染与处理提供计算能力。由于GPU具有的强大并行计算能力,在AI时代被广泛用于AI算力,为AI模型训练和推理提供高速数据计算支持。部分新一代的数据中心级GPU已经不再提供显卡接口,而是专用于人工智能深度学习。
表3是英伟达GPU卡的分类。对标AI算力基础设施分类,数据中心级GPU适用于AI训练设施和AI推理设施,专业级适用于AI推理设施,消费级适用于AI桌面设施。AI嵌入设施可采用英伟达的边缘计算专用设备(如Jetson系列)。
表3 GPU的类型
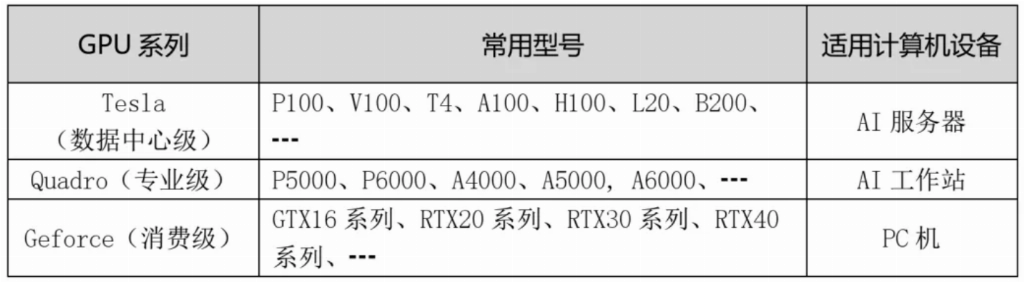
表4部分GPU的性能指标。
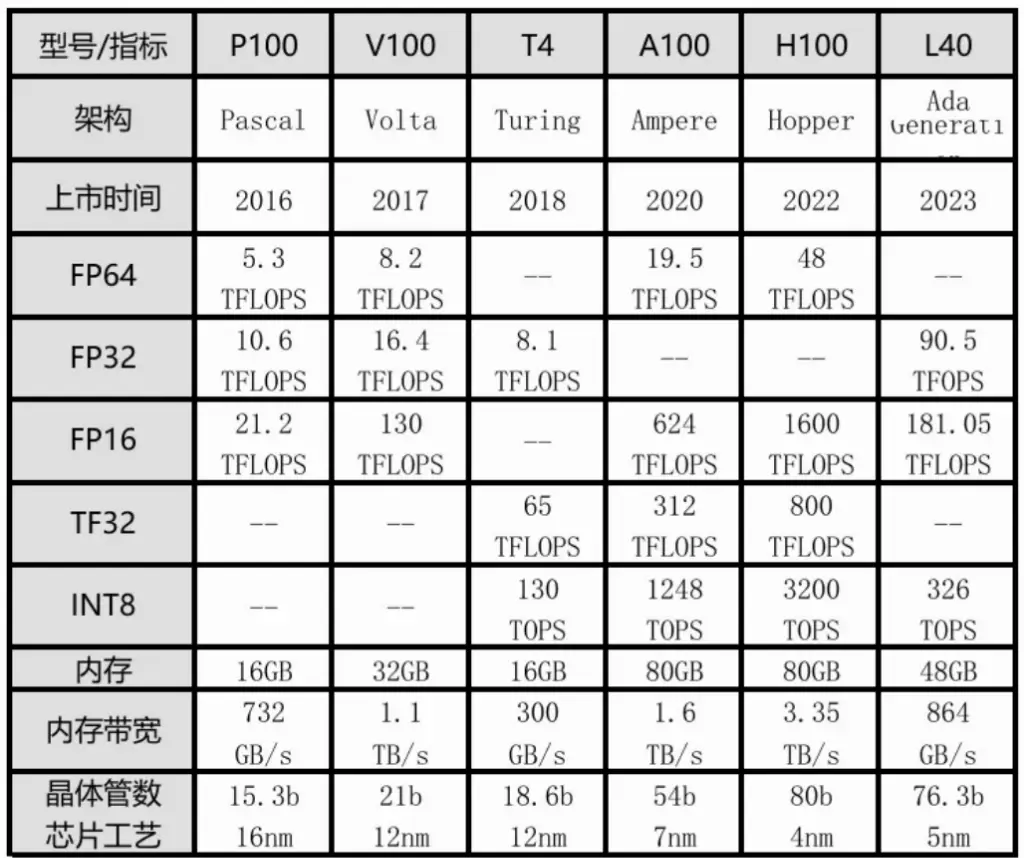
表4为GPU的性能指标 (表内参数值仅供参考,以英伟达官方公布为准)
表5 GPU的其他主要指标
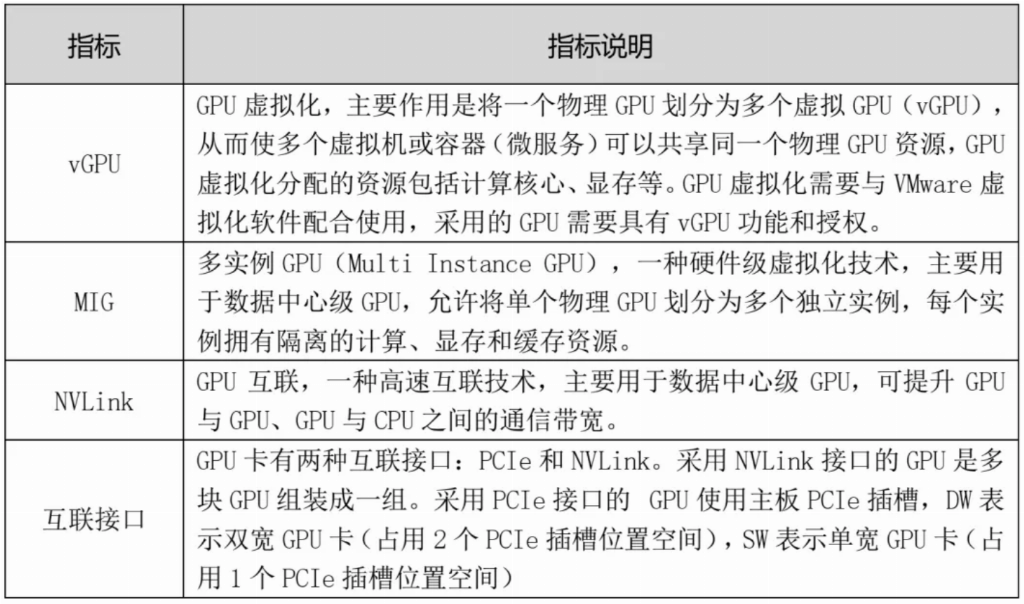
表5列出GPU的其他主要指标。表5所列的指标并不是每种型号GPU都具备的,需要时应查询英伟达官网资料。
GPU的选型主要是依据AI模型算法的基础框架(如英伟达GPU的CUDA)、AI算力服务器的用途(训练、推理或微调等)、模型算法类型(机器学习或深度学习)与精度、应用场景以及货源情况等因素综合考虑。对于企业级的AI中心服务器,可以采用数据中心级GPU,保证有一定扩展空间。此外,还要注意即使是相同品牌的GPU,但型号不同,甚至内存容量不同,通常都不能直接合并使用(例如,将几张同型号但显存容量不同的GPU显存相加),需要通过数据并行或模型并行的方法解决。遇到这方面的问题,建议先咨询GPU供应方。
3)算力卡的开发环境
算力卡的开发环境通常指的是用于运行和开发人工智能应用程序的计算资源和软件配置。算力卡大厂都有与自家算力卡配套的开发环境,包括英伟达GPU的CUDA架构,华为NPU的CANN架构和AMD GPU的ROCm代码平台等。英伟达GPU的开发环境主要围绕其专有的CUDA(Compute Unified Device Architecture)平台构建。图2(左图)描述了英伟达GPU的开发环境。
CUDA提供了一个并行计算平台和编程模型,开发者可以使用英伟达GPU的处理能力来加速计算密集型应用。英伟达的CUDA平台与GPU深度绑定,对于使用CUDA平台开发的应用程序(算法模型),若使用其他GPU,需通过适配层将CUDA代码转换为兼容目标GPU的指令,如图2(右图)所示。
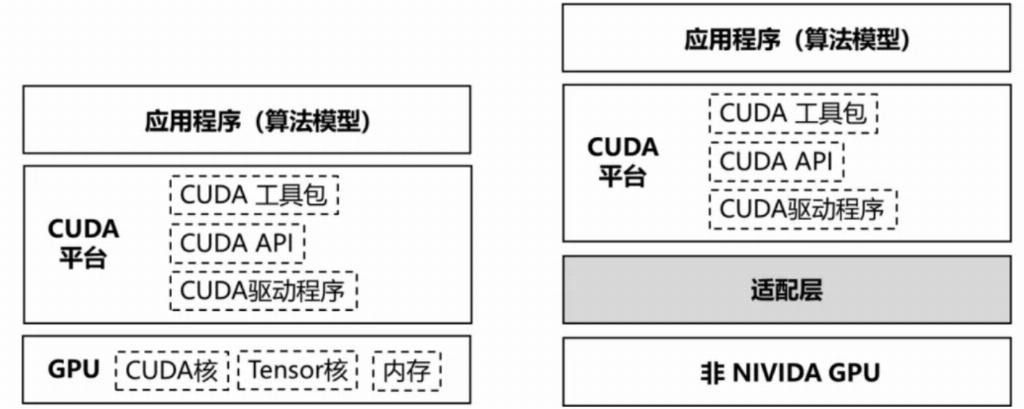
图2 (左图)英伟达GPU的开发环境,(右图)非英伟达GPU通过适配层兼容CUDA开发环境。
三.小结
今年以来, 以DeepSeek为代表的大模型以其技术优势和成本效益,在各行业和场景中得到广泛应用。基于内部数据安全的考虑,许多机构在应用大模型时,采用了内部部署方式。如何建设和配置AI算力设施,成为技术工程师关心的问题。本文对AI算力核心的算力卡相关内容做了介绍,希望对大家有所帮助。
作者简介:王咸宁(Xianning Wang),就读于密歇根州立大学(MSU)工程学院。开源IT技术探索者,致力于AI技术在应用领域的研究。
免责声明:本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其内容真实性、完整性不作任何保证或承诺。由用户投稿,经过编辑审核收录,不代表头部财经观点和立场。
证券投资市场有风险,投资需谨慎!请勿添加文章的手机号码、公众号等信息,谨防上当受骗!如若本网有任何内容侵犯您的权益,请及时联系我们。
相关文章
-
“阿里巴巴集团员工总数是多少?”
2025-03-1912阅读
-
英伟达推出机器人通用基础模型 GR00T N1
2025-03-1912阅读
-
英伟达黄仁勋:2026 年下半年推出新以太网芯片
2025-03-1912阅读
-
英伟达、谷歌 DeepMind、迪士尼合作机器人 Blue 亮相
2025-03-1912阅读
-
英伟达下下一代 AI 芯片架构命名 Feynman,2028 年登场
2025-03-1912阅读
-
百度文心4.5与X1登场后,大模型第一梯队的竞争再升级?
2025-03-1912阅读
-
工业互联网板块3月18日涨0.82%,东土科技领涨,主力资金净流出14.39亿元
2025-03-1912阅读
-
经济增长担忧打击市场情绪,印尼综指盘中跌至熔断,刷新3年多新低
2025-03-1912阅读
-
2025年私域大模型部署白皮书-超云
2025-03-1912阅读
-
英伟达 Grace Blackwell 方案已全面投产,黄仁勋展示各厂商机架
2025-03-1912阅读

