写在开头
RTX 50系的推出引爆了整个硬件圈,特别是RTX 5090显卡的推出,更是一卡难求。全新服务器级别的Blackwell架构,极致的性能表现,还有DLSS 4、Reflex 2等黑科技加身!每一项都足够点燃玩家的热情。不过极致的性能也伴随着极致的价格,让不少玩家也是望而却步,那相对更便宜的次旗舰RTX 5080能否应付发烧游戏玩家、创作者乃至AI开发者的需求呢?

本次评测就带大家看看RTX 5080的表现如何,我们上手的是微星GeForce RTX 5080超龙SOC显卡,熟悉微星的玩家应该对超龙系列不陌生,该系列自推出以来,便以卓越的性能和精湛的工艺,赢得了广大用户的高度认可与赞誉,成为微星显卡家族中的王牌系列。而这款GeForce RTX 5080超龙SOC,更是超龙系列中的璀璨明珠,堪称旗舰中的旗舰,全面且过硬的实力就是它的底气所在。
规格介绍
开始前,照例讲讲新显卡的规格。GeForce RTX 50系显卡采用了此前NVIDIA在AI领域推出的Blackwell架构,以大卫·布莱克威尔命名,其是一名受人尊敬的数学家和统计学家,在博弈论和统计学领域留下了不可磨灭的贡献,NVIDIA用其名字命名这一架构反映了新平台的开创性和先进的计算能力。Blackwell可以说是NVIDIA近年来更新幅度最大的GPU架构了,相比起之前的架构来说,划时代的引入了神经网络着色器,力图为游戏开创先进、高效更有逼真的渲染方式,带给玩家全新的游戏体验。

相比前代Ada架构,Blackwell的升级聚焦于四大方向:分别是AI算力的爆发、光线追踪技术的革新、显存能效的提升以及划时代的神经网络渲染。
第五代Tensor核心
其中AI算力的爆发就不得不提到Blackwell架构上的第五代Tensor核心,新一代Tensor Core添加了对FP4浮点运算精度的支持。FP4是一种较低的量化方法,类似于文件压缩,可以减小模型推理过程中数据存储和计算量大小,提高计算效率,降低该过程对显存的要求。与大多数模型默认使用的FP16相比,FP4使用的显存不到其一半,并使GeForce RTX 50系列GPU的性能相比上一代提升高达2倍。
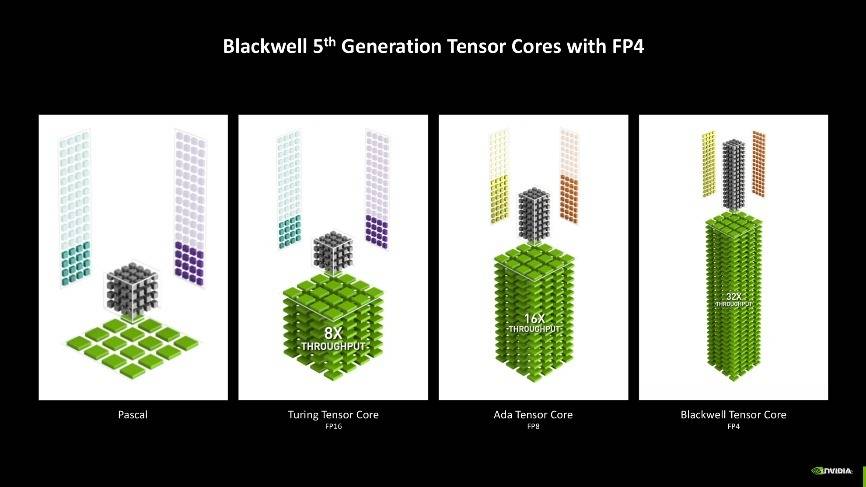

第四代RT核心
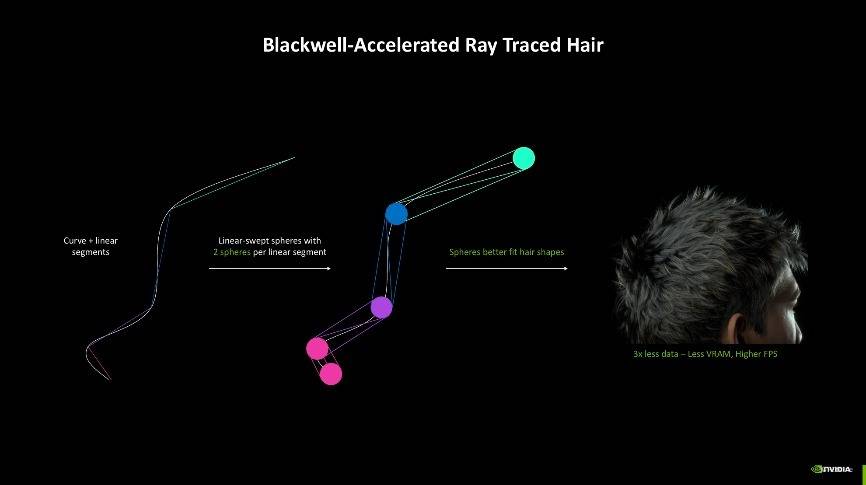
而光线追踪技术的革新则仰赖于第四代RT核心的加持,相较于第三代RT核心来说,Blackwell架构的第四代RT核心主要提升了检测光线、路径与三角形相交的效能,过往在检测时往往只能检测单个三角形,一旦场景复杂,检测能力不足就容易导致渲染出错等问题,而现在检测能够以簇集方式进行,检测效率更高。同时还有三角形簇集解压缩引擎加持,其新增了Linear-swept Spheres(LSS)功能,可以减少渲染毛发所需的几何图形数量,并使用球体代替三角形以获得更准确的毛发形状拟合,能够让显卡发挥更好的性能但只消耗较小的显存占用。
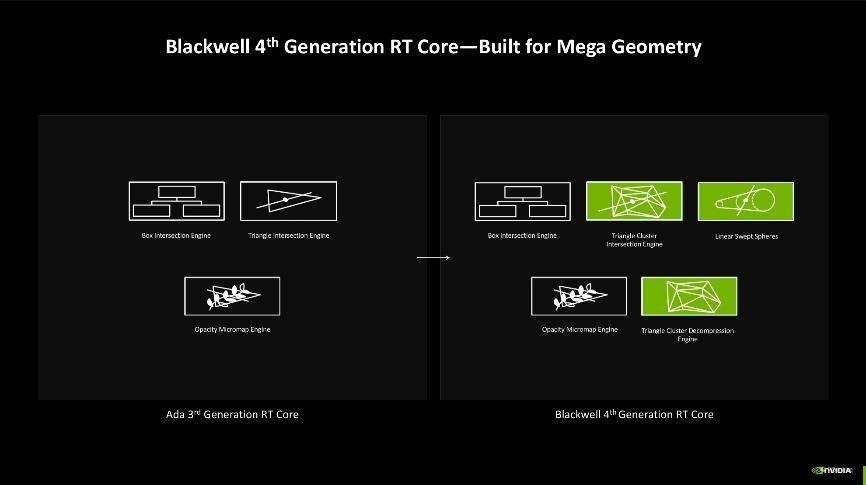
综合来看,Blackwell架构的光线追踪多边形相交效率是上一代Ada架构的2倍,是Turing架构的8倍,同时还可以节省25%的显存使用率。
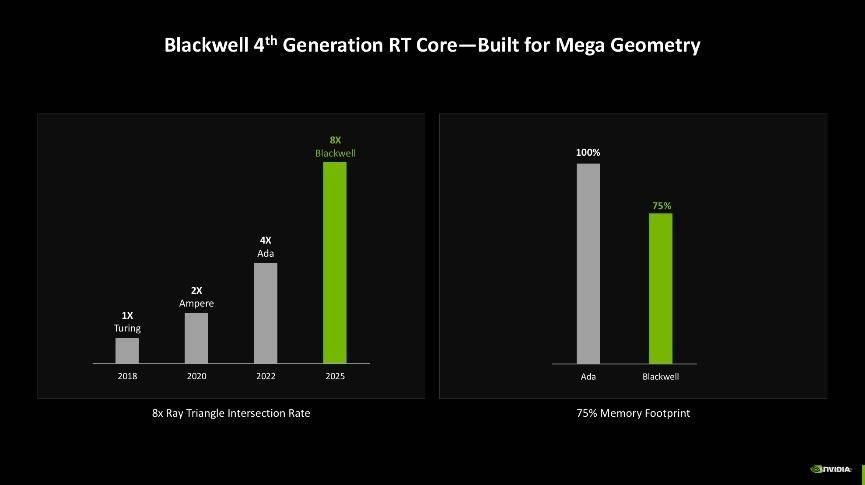
第四代RT核心的改进主要是为实现更好的光追效果。其中有两项新技术能够受益,第一项是RTX Mega Geometry技术。随着光线追踪游戏场景的几何复杂性不断增加,游戏画面中几何图形的计算量也呈现出快速增长的趋势。而RTX Mega Geometry技术能够加速构建边界体积层次结构(BVH),使得在实时渲染中可以处理多达100倍的三角形数量。
该技术的出现,也使得开发者能够在游戏场景中使用更复杂的几何图形,而不会影响游戏帧率。过去需要一个个算BVH,现在RTX Mega Geometry能够智能地在GPU上批量更新三角形簇,减少了的负担,既保证了性能,也兼顾了图像质量。相信随着这些技术的不断发展和应用,未来的游戏将能够呈现出更加逼真和细腻的视觉效果,同时保持高效的性能表现。
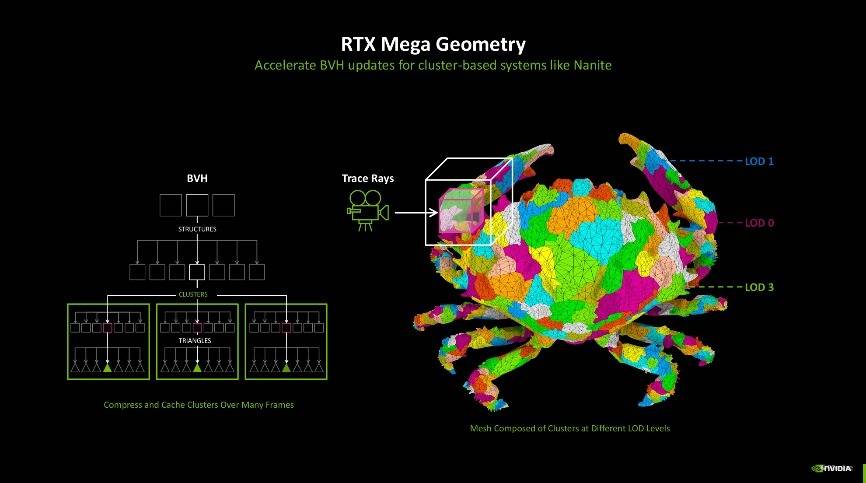
另外一个能够受益的技术则是Curve Primitive,方便光追在曲面中的应用,例如一位男士的头发可能需要多达400万个三角形,再加上光线追踪技术,画面所需要的运算负载极大。NVIDIA则通过第四代RT核心中的Linear- Swept Spheres(线性扫描球体)技术有效减少了渲染头发所需的几何体数量,以球形代替多边形,更贴合头发的形状,从而将占用量大幅缩减至三分之一,并进一步提升了实际帧数,让头发的渲染效果更加自然流畅。
GDDR7显存
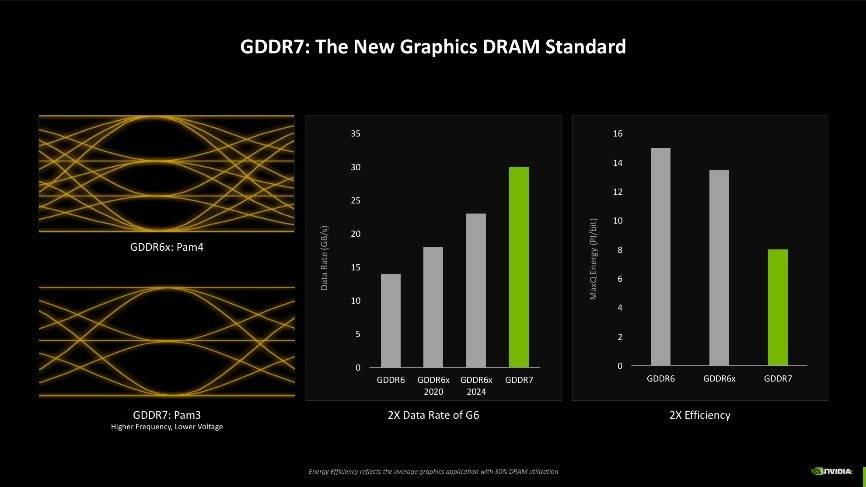
第三点改变则是显存效率的提升,Blackwell架构中还首次加入了对GDDR7显存的支持,此前GDDR6显存的信号编码为NRZ/PAM2,而RTX 40系上的GDDR6X则是PAM4编码。最新的GDDR7显存,信号编码改成了PAM3,NRZ/PAM2每周期提供1位的数据传输,PAM4每周期提供2位的数据传输,而PAM3每两个周期的数据传输为3位。说人话就是,新的编码机制可以使杂讯失真比减小,信号品质更清晰,同时还能带來更高的显存运行频率以及更低的电压,根据NVIDIA的介绍,使用GDDR7显存后,数据传输速率可达GDDR6时的2倍,并且功耗接近GDDR6的一半,经典加量还减价。
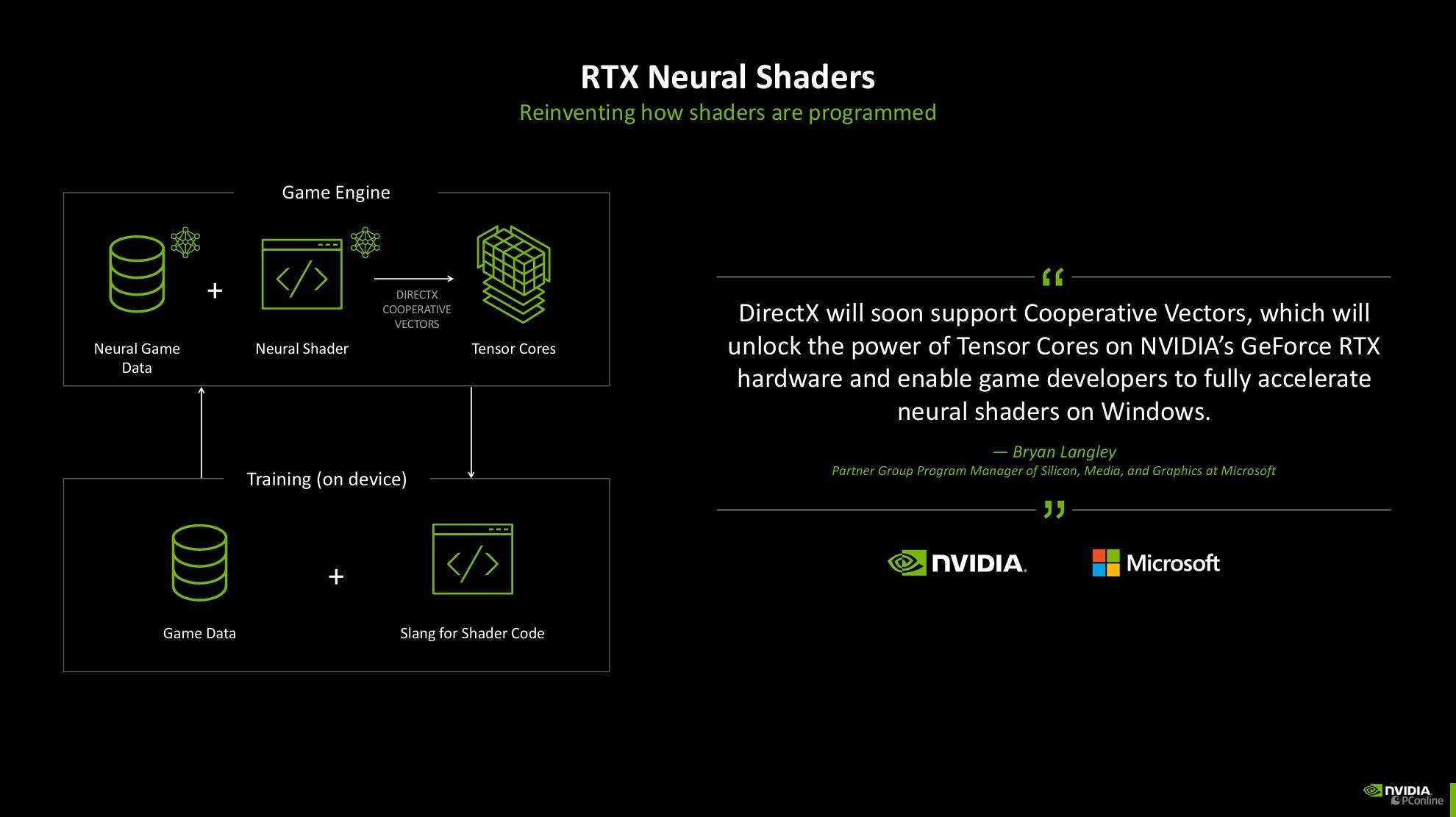
神经网络着色器
接着我们再细说一下这一代架构最大变化,NVIDIA这次将Blackwell架构的SM单元直接称为神经网络着色器。相比较于之前的可编程着色、CUDA统一着色、通用计算着色来说,其最大的变化就是引入了AI,AI将会彻底改变GPU的着色方式。
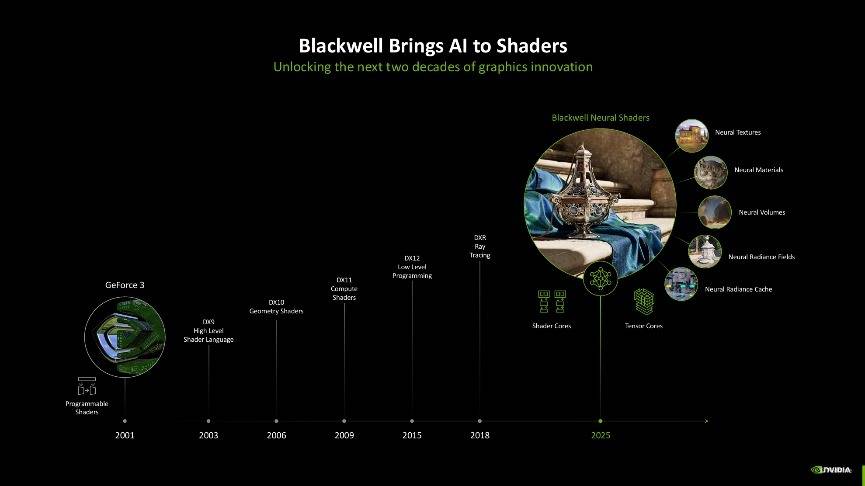
在Blackwell架构中,NVIDIA 进一步拓展了神经网络渲染的范畴,引入了诸多创新元素,包括神经网络纹理压缩(Neural Textures)、神经网络材质(Neural Materials)、神经网络体积(Neural Volumes)、神经网络辐射场(Neural Radiance Fields)以及神经网络辐射缓存(Neural Radiance Cache)等,这些元素共同构成了神经网络渲染中神经网络着色的重要呈现方式。
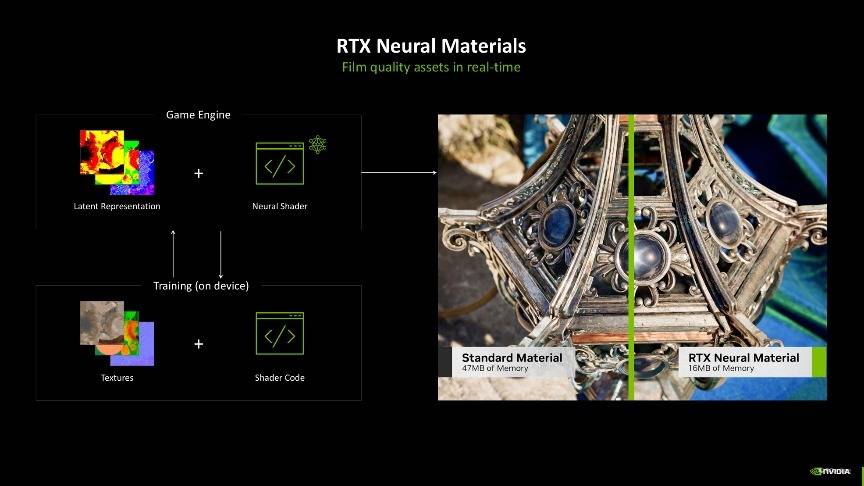
这里举个例子让大家能够更简单的理解神经网络渲染,过去复杂的物品或大量异材质的贴图往往会占用相当大的内存空间,如果叠加光追的话,计算量将会更大。然而,得益于神经网络渲染技术中的神经网络材质功能,这一问题得到了显著改善。开发者可以先在离线渲染出物品的光照数据,然后再用这些数据训练一个小的AI模型,游戏运行时只要实时调用这个AI模型当场推理就好了,这样就能还原出想要的光照效果了,再配合神经网络纹理压缩技术,就能显著降低实际生成的材质数据量,从而在占用更少显示内存的同时,实现了细节更丰富的材质表现,达到了实时生成如电影般细腻素材的效果。
目前神经网络渲染技术已经得到了微软的大力支持,未来也将会加入到DirectX中,玩家能够体验到更真实的游戏世界。
而在硬件层面,由于神经网络渲染的加入,Blackwell架构的SM单元相较于RTX 40系的Ada架构还是有不小变化的,Ada架构内的SM内,SM单元会拆分成一半的CUDA专门用于处理FP 32(单精度浮点数),另一半则依需求动态调整去处理FP32和INT32(32位整数)。而在Blackwell架构上,SM单元则改成了CUDA核心可以完全依需求动态处理FP32和INT32的形式。
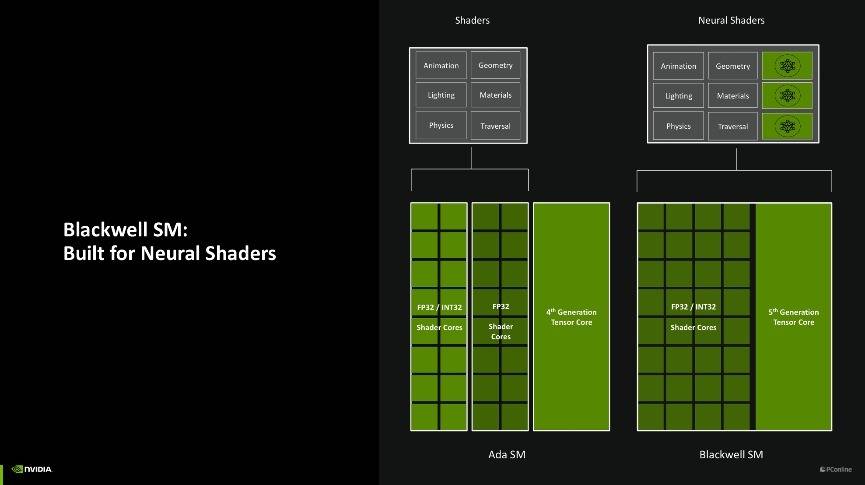
另外一个改进是,过往的着色工作往往只有SM单元的Shader在处理,而Blackwell架构上引入了神经网络渲染以后,使得Blackwell架构上的第五代Tensor核心也能共同分担着色工作,大大提高了着色效率。
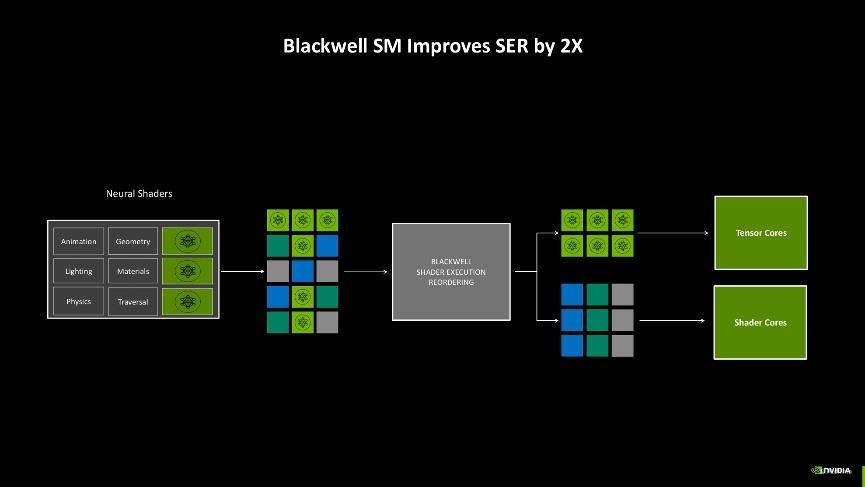
这样改进的好处是,Blackwell架构能够进一步针对神经网络渲染工作进行排序,即把传统的着色工作分配给Shader,而需要动用神经网络渲染的工作负载则可以给到Tensor核心上,两种核心同时运用,效率最高可以提升2倍之多。并且得益于Tensor核心也加入了可编程渲染管线,现在开发者或API也能更好的调用Tensor核心,未来游戏内我们能见到的AI技术势必越来越多。
先进的AI管理处理器
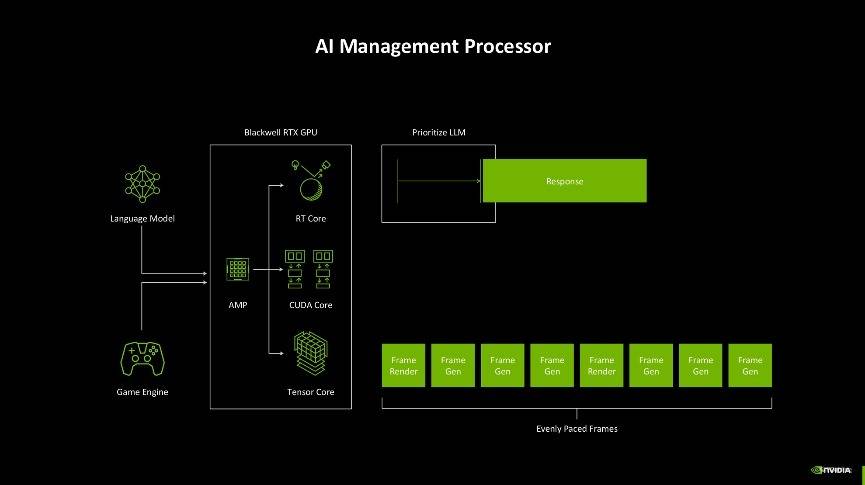
此外,AI的应用也越来越多,不仅游戏中应用AI技术,现在连可编程渲染的过程里也引入了AI,因此如何去分配显卡内部多样化工作就成了一个问题。如过往显卡在开启DLSS玩游戏时,其中应用到的语言模型和游戏引擎需要同时与GPU的不同核心交互,生成游戏帧,但是往往很难做到每一帧都有一致的生成时间,亦或者是游戏AI对话的响应不够及时,这些情况都会造成游戏体验不友好。

而Blackwell架构为了解决这一问题,引入了AI管理处理器(AMP)。它能够实时调度资源,确保在神经网络渲染、帧生成和 AI 驱动的游戏交互中实现智能化的任务分配。这种设计不仅带来了更高效的性能输出,还让显卡在游戏渲染和 AI 运算之间实现了绝佳的平衡,确保帧的间隔均匀,对话类型的AI能够及时响应,玩家的游戏体验一致性能够比较好的保障。
GeForce RTX 5080规格
说了这么多,接下来给大家介绍一下GeForce RTX 5080的硬件规格,不同于老大哥采用的GB202核心。GeForce RTX 5080采用的是GB203,核心代号为GB203-400-A1。在架构上拥有7个GPC,但每个GPC包含的TPC并不相同。GeForce RTX 5080上总共集成了42个TPC,84个SM单元,336个TMUs纹理单元,112个ROPs光栅化处理单元,10752个CUDA核心。

在工艺制程方面,新的GB203核心沿用了TSMC 4nm 4N NVIDIA Custom Process工艺。核心面积为378mm2,内部晶体管数量则有456亿,在这么小的空间内堆下如此之多的晶体管,可以说是绝对工业艺术品的集大成之作了!早前看过我们RTX 5090 D的玩家应该都知道它的功耗达到了前所未有的575W,不过作为次旗舰的GeForce RTX 5080就保守一些了,仅比上代提升了40W,TDP设定为360W,玩家选购时配备一个850W的电源绝对是绰绰有余了。
除此之外,GeForce RTX 5080还配备了全新的GDDR7显存,显存等效频率可达32Gbps,同时16GB的大容量显存也能为玩家提供高分辨率下的极致帧率,同时还能兼顾大部分AIGC用户的应用需求,多重黑科技加持下,高分辨率出图也可更加高效。同时视频输出接口也进行了升级,能够兼顾高分辨率与高刷新率,后续开箱显卡时我们会详细介绍。

至于我们本次上手的微星GeForce RTX 5080超龙SOC与MSRP版本的GeForce RTX 5080的区别则主要体现在用料配置上更加高端,同时频率也会比较高,毕竟是带了“SOC”后缀的显卡。其基础频率与MSRP版本一致,均为2295MHz,不过Boost频率提升至2745MHz,提升了不少。
显卡外观赏析
在外包装设计上,微星GeForce RTX 5080超龙SOC显卡以白色为基底,配合NVIDIA特有的绿色条纹图案以及银色的超龙SUPRIM标志,简约但又大气,右上角的SOC标志则代表显卡为超频版,频率会高于NVIDIA的官方设置。

包装的背面就比较常规了,主要是一些显卡的卖点介绍以及RTX 50系显卡的参数,旨在让玩家更全面的了解自己手上的这款利器。

刚打开包装就看到“CHANGE THE GAME”的SLOGEN,意为“颠覆视界”,微星带给玩家的不仅仅只在于游戏,更是让身兼Gamer的用户展现出自己的生活品味。

顶部则是超龙SUPRIM系列的标志,这里给不熟悉的玩家介绍一下,SUPRIM系列是微星在2020年推出的全新系列,SUPRIM系列拥有超高规格的硬件性能,在产品外型上更是具有独创性,放弃过多的炫彩灯效与复杂的装饰,以内敛高雅的质感精品形象面世。而SUPRIM系列产品名称则是由三个词组合而成,分别是:Superior、Profound、Impossible,代表了SUPRIM系列的卓越设计理念、深刻美学设计以及超越的性能表现。

继续开箱,包装内除了显卡本体之外,还有两样附件,分别是1条3×8Pin转12V-2x6接口转接线以及1个迷你款的显卡支撑杆。其中转接线采用了与微星自家新款ATX 3.1电源同款的双色插头,帮助用户确认显卡是否插紧,避免连接事故的发生,材质用料也升级了,耐热度相较于普通款要好19%。而显卡支撑杆对比上代则变得小巧了许多,其最大支撑高度达98.6mm。

终于见到主角——微星GeForce RTX 5080超龙SOC,设计语言与上代超龙还是比较类似的,整体采用银黑配色设计,同时微星还根据钻石切割的几何结构为灵感,应用了大量棱角分明的切割线条进行装饰,让整张显卡焕发出不同的质感,观感上也更加硬朗,尽显精湛工艺和优雅气质。

散热风扇部分,微星也进行了升级。微星GeForce RTX 5080超龙SOC标配三把暴风7散热风扇,每把风扇直径105mm,厚度更是高达15mm,单从规格上就不难看出它的实力强劲。除此之外,每把散热风扇还标配7片扇叶,采用环形连叶设计,扇叶表面还有龙爪纹理,能够带来更佳的气流效果与更低的噪音表现。

翻转视角看看显卡的背部,其背板采用两种工艺打造,分别是拉丝与磨砂。在不同的光线下,显卡背部会呈现不同的视觉效果。,拉丝纹理与精确的切割线相契合,造就了低调的精致感。

在显卡背部的左侧则是镂空的散热窗口设计,这样做的目的是加速显卡内部的空气流动,达到提升散热的目的。并且镂空窗口附近还有SUPRIM标志,既是点缀,也是辨识度的一种。

看完了整体,再看局部。在背板上还能看到一个小缺口,这是显卡BIOS切换的地方,微星GeForce RTX 5080超龙SOC提供GAMING以及SILENT两种模式可选,玩家可以按需选择。

双BIOS切换开关的旁边则是显卡的供电接口,为12V-2×6接口,也就是常说的16Pin,单口供电能力可以达到600W。

当然,参与供电的不止12V-2×6接口,显卡底部的PCIe金手指也会参与部分供电。并且这一代显卡的PCIe接口升级成为了5.0速率,这也是首次在RTX 50系显卡上应用,能够带来更高的传输速率,另外仔细看金手指的形状,它和上一代的显卡也有些微的变化。

视线转到显卡的两侧,可以看到顶部除了有熟悉的“GEFORCE RTX”标识外,还多了一块灯牌,上面印有“SUPRIM”字样。

底部则是密密麻麻的散热鳍片加持,看起来非常唬人,整张卡拿在手上也是沉甸甸的,很有份量感,散热效果应该不错。

值得一提的是,微星在设计这款显卡时,对辨识度以及装饰也拿捏得相当到位。例如显卡正面的风扇底部以及显卡侧边都有“SUPRIM”的标识。


显卡的另一边则是经典的SUPRIM标志,其设计创意来源于钻石晶体的几何形状,点亮显卡后还能显示RGB灯效,犹如不同颜色的珠宝镶嵌在这块显卡之上。

视频输出接口方面,还是经典的3个DP加1个HDMI的配置,不过规格上有了升级,微星GeForce RTX 5080超龙SOC采用的是DP 2.1b与HDMI 2.1b规格。理论上,这一代显卡的视频输出接口可以轻松实现4K 480Hz和8K 240Hz超高分辨率与超高刷新率的需求。

最后再带大家看看这款显卡的三围,从这个角度看去,显卡的厚度足足有3.5槽以上,查询参数可知,这款显卡的规格是360*145*76mm。

重量方面,裸卡重量2632g,不得不说还是比较厚重的,玩家装机前最好先测量一下自己机箱的兼容性。

显卡上机效果
下面将微星GeForce RTX 5080超龙SOC上机看看,通电后可以看到风扇的周围有一小圈灯带,当显卡竖装时即可欣赏到RGB灯效与金属相互碰撞的高级感,并且灯效还支持自定义调节,想要什么效果只要在MSI CENTER软件设置就可以了。


顶部的SUPRIM灯牌也同步亮起,给单调的显卡外壳增添了一抹艳丽,即便玩家是横装显卡时也能一睹RGB的风采。

侧边还有一个超龙SUPRIM系列的LOGO灯牌,辨识度同样拉满,微微凸起的设计更像是一块宝石,让人一眼看去就知道这是微星GeForce RTX 5080超龙SOC旗舰级显卡。

整体来看,微星GeForce RTX 5080超龙SOC的灯效设计不像其他显卡那么张扬,低调内敛中透露着奢华质感,恰到好处的RGB点缀给人一种“西装暴徒”的即视感。

显卡拆解赏析
拆解部分,首先看看显卡的PCB设计。有一说一,微星GeForce RTX 5080超龙SOC的PCB在一众RTX 5080中也是比较特殊的。其为越肩设计,不过得益于RTX 50系紧凑的设计,因此这块PCB上余有不少空间。

无论是正面还是背面,PCB上都安排了各式各样的电子元器件,布局紧凑且焊点饱满,用料扎实可靠,这款显卡还特别在12V-2×6接口附近配备了FUSE保险,可以提高显卡的安全性。并且PCB内部还应用了增厚的2盎司铜层,可以提高导电性,从而改善散热性能和可靠性。

PCB的中央则是本次测试的重点,GB203-400-A1核心,它就是微星GeForce RTX 5080超龙SOC的大脑,由TSMC 4N工艺打造,拥有10752组CUDA核心,稍多于RTX 4080 SUPER,通用的图形性能自然更强。

核心的四周是8颗GDDR7显存,由三星提供,型号为K4VAF325ZC-SC32,内部是512M×32的架构,数据频率可达32Gbps,显卡的默认设置为30Gbps。

供电部分,作为绝对的旗舰,微星GeForce RTX 5080超龙SOC采用16+3相供电设计。

并且每一相供电都使用了低噪稳定的HCI电感以及高效率的DrMOS,DrMOS型号为MP87993,最大支持90A电流。


主控芯片则是来自MPS,型号为MP29816-A,位于PCB的背面。

下面看看这款显卡的散热设计,整张显卡的散热系统还是相当有份量的,率先映入眼帘的就是正中间这个大面积且非常厚实的均热板。根据微星介绍,这个均热板的厚度足足有9毫米,能够快速带离核心及显存等元件的热量。

另一侧则是我们见过的镂空窗口设计,这样正面的散热风扇能够最大限度的吹透内部的鳍片,从而加入显卡内部空气流动,提升散热效能。

想要完整取出散热器,我们还需要卸下固定架,有一说一这个设计还是非常到位的,能够进一步增强显卡的刚性架构,防止PCB弯曲,保障你的显卡安全。

整个显卡散热模组还是非常硕大的,微星针对其配备了广布式方形热管,这样设计的目的是,方形热导管布局更大,能够充分和均热板接触,从而提升整体冷却效能。

内部共有11根核心热管,分别是7条8mm直径热管与4条6mm热管的组合,为GPU核心及显存散热提供了高效保障。

散热鳍片则依然使用了微星一贯的波浪形,尾端鳍片则采用翼状设计,并设置有高低落差的间隔排列以减少气流的阻碍。

主动散热就是外观部分给大家介绍过的暴风7散热风扇了,搭配上面介绍的方形核心热管、真空腔均热板散热技术以及独特的散热鳍片形状,共同为每位玩家提供了无与伦比的散热性能和极其安静的使用体验。

测试平台介绍
开始性能测试前介绍一下本次的测试平台, CPU使用的是目前毫无争议的游戏神U—— Ryzen R7-9800X3D,则是来自微星的MPG X870E CARBON WIFI 暗黑主板。内存为G.Skill的幻锋戟Z5 RGB DDR5,在这块主板上能轻松达成DDR5-8000 C38的成绩,并且我们这次选用的是24G×2的套条,确保这张显卡能够释放全部性能。

完整配置如下所示:

理论性能测试
开始测试前,照例还是要“认识”一下这张显卡。从GPU-Z的信息中可以看到微星GeForce RTX 5080超龙SOC的基准频率为2295MHz,Boost频率为2745MHz,这个频率不仅比公版RTX 5080要高,对比前代RTX 4080的话,更是还是提升了不少。除此之外,由于是超频版显卡,因此这张显卡的TDP为360W,不过可以进一步解锁至400W,为超频预留了充足的空间。
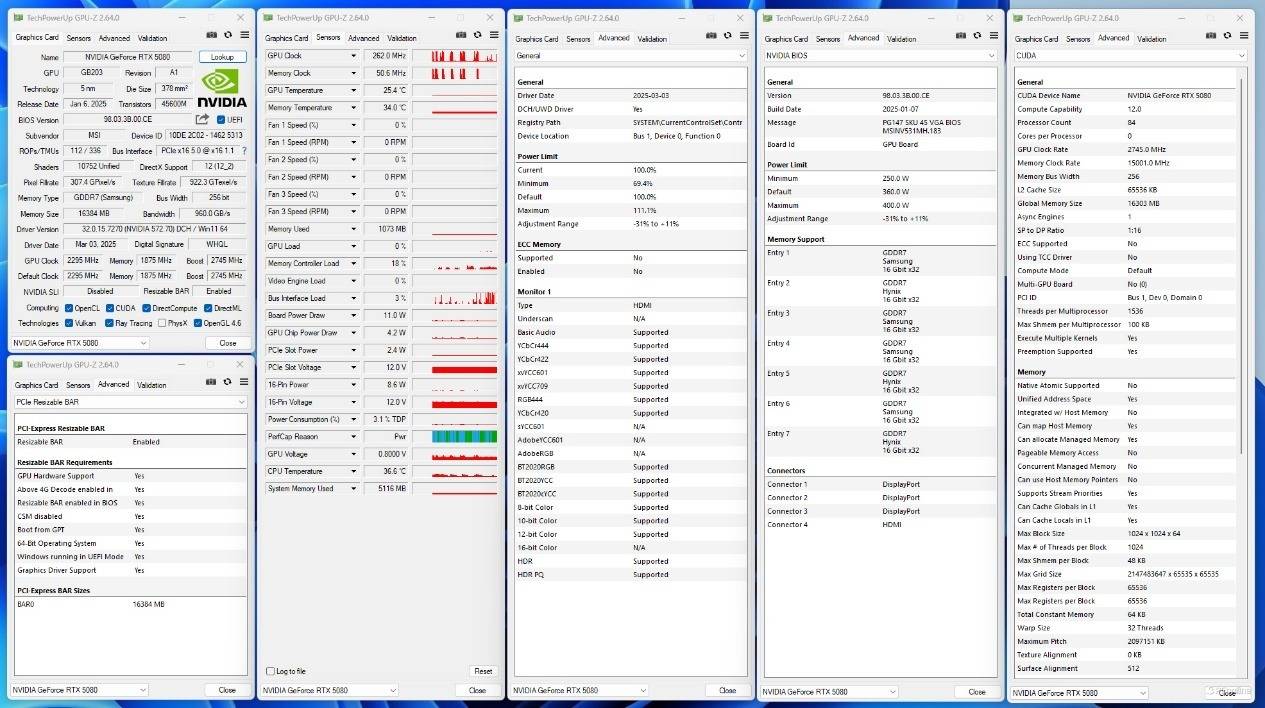
理论性能部分看3DMark,在Fire Strike系列测试中,微星GeForce RTX 5080超龙SOC表现非常亮眼,其中4K分辨率下领先RTX 4080约26%,2K下可以领先RTX 4080约30%,最夸张的是1080P,差距可以拉大至32%。而在以DX12为代表的Time Spy测试中,新显卡同样逆天,对比RTX 4080 SUPER或RTX 4080显卡均能做到领先约16-18%,性能提升还是非常可观的。
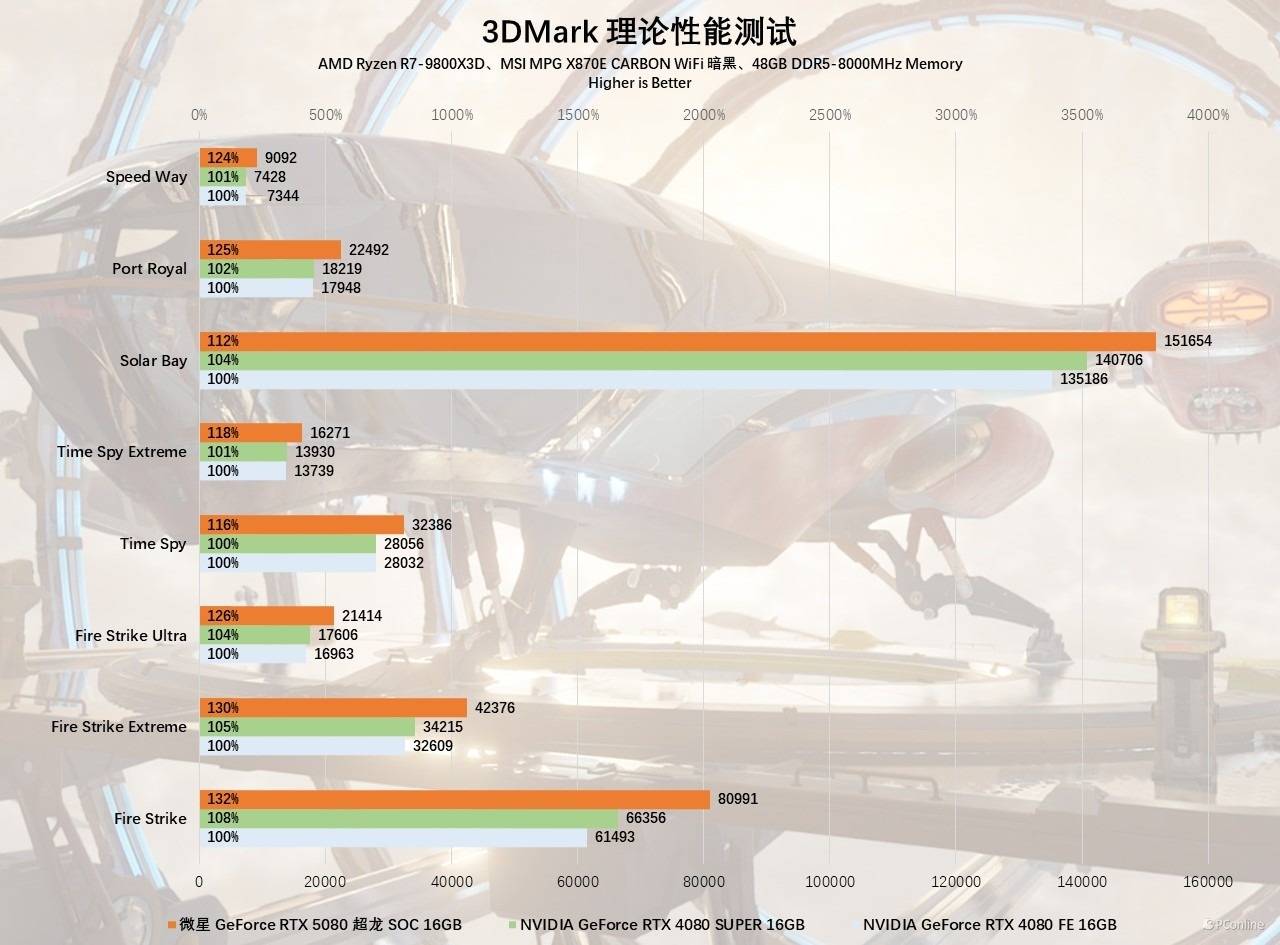
除了Time Spy以及Fire Stirke提升明显外,光追项目也有史诗级的提升,微星GeForce RTX 5080超龙SOC得分22036,这个成绩遥遥领先于RTX 4080甚至是RTX 4080 SUPER,分别领先23%和25%。而在最新的Speed Way测试里,同样也有超24%的性能提升。
DLSS 4专项测试
看完了理论性能部分的测试,接着我们再来看看本次RTX 50系显卡最“顶”的升级,DLSS 3在RTX 40系显卡上引入了帧生成技术,能够依靠AI在两帧之间生成一帧AI帧,从而实现帧数的翻倍,用过的玩家都说好!不过由于每生成一个新的帧都需要光流加速器和 AI 模型参与,因此生成多帧的开销相当高昂,而过高的性能开销会带来瓶颈,导致帧率提升受限。
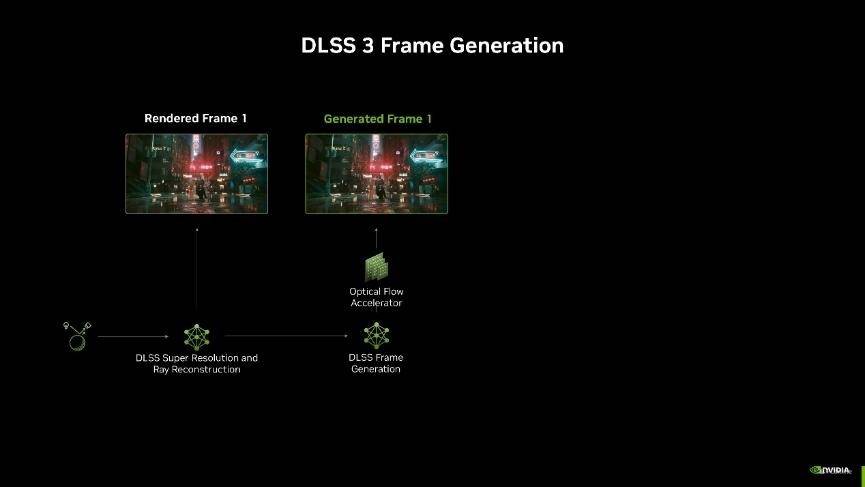
而这次DLSS 4全新升级,引入了多帧生成技术,它可以利用 AI 为每个渲染帧额外生成多达3帧!相比传统渲染的方式,能够最多实现8倍的性能提升。并且每次渲染额外帧只需要AI模型执行一次,就能输出三帧画面,因此无论是对性能、显存的开销还是延迟都比之前要好了许多。
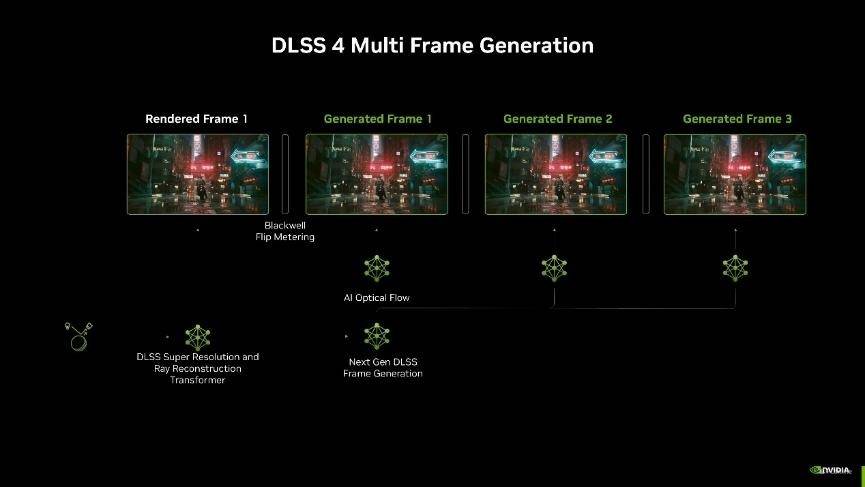
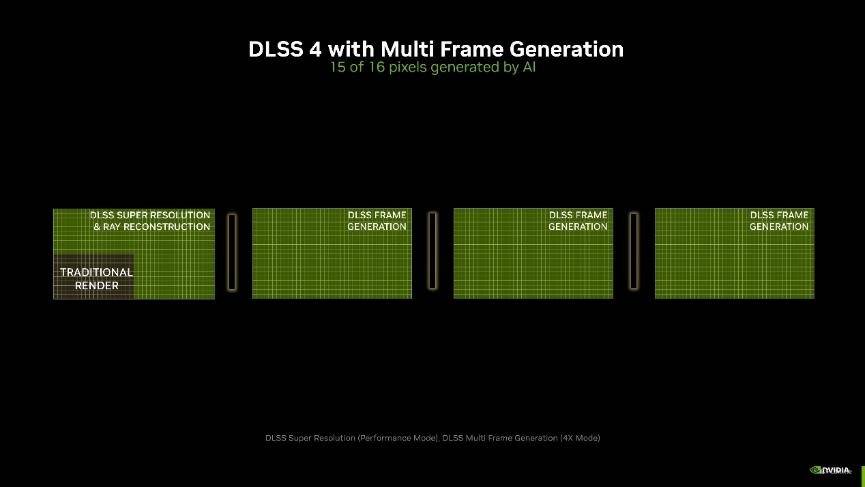
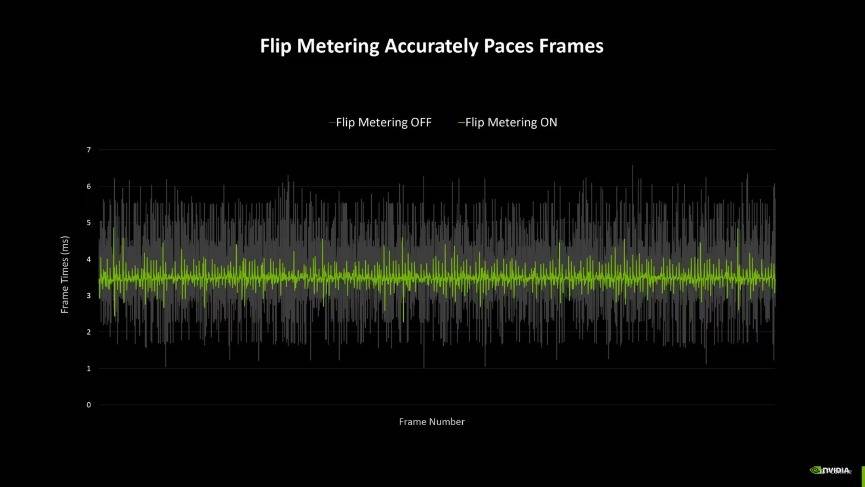
另外,由于多帧生成技术,输出的帧多了,要给每一帧都安排一个合理的间隔刷新才能让观感更好。因此NVIDIA还引入了专属的Flip Metering来代替CPU Pacing,它将帧节奏逻辑转移到显示引擎,让GPU能够更精确地管理显示时间,尽可能的将每一帧画面的生成时间保持一致,从而提高整体游戏视觉的流畅感。不过由于Flip Metering是硬件级的控制器,因此DLSS 4的多帧生成目前只有RTX 50系显卡支持。
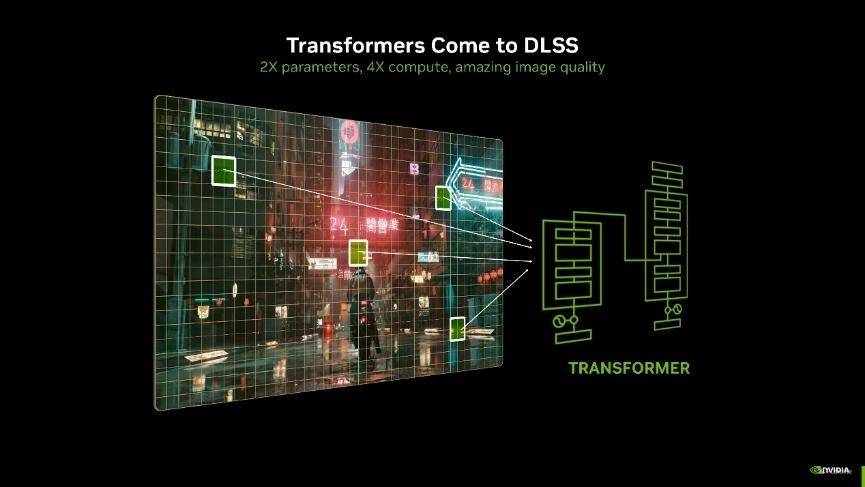
同时DLSS 4 还引入了图形行业首个 Transformer 模型实时应用。熟悉AI的应该对它很熟系了,它在AI生成领域已经应用多年了。基于Transformer架构的 DLSS 超分辨率和光线重建模型,相比之前DLSS使用的卷积神经网络(CNN)模型来说,具备2倍的参数量和4倍的计算量。在游戏场景中,能够提供更高的稳定性、更少的拖影、更高的细节和更强的抗锯齿能力,使画面更加清晰、流畅和逼真。
不过虽然DLSS 4的多帧生成功能是RTX 50系显卡的独占功能,但新的Transformer模型将会逐步下放至DLSS 3、DLSS 2等,将适用于所有GeForce RTX显卡。并且根据NVIDIA的说法,超过75款游戏和应用将在GeForce RTX 50系列开售时支持DLSS 4的全新DLSS多帧生成功能,包括《赛博朋克2077》《战神:诸神黄昏》《心灵杀手2》《霍格沃兹之遗》等,《黑神话:悟空》也将于今年晚些时候升级支持 DLSS4的多帧生成。随着时间的推移,支持DLSS 4的游戏和应用数量将不断增加。

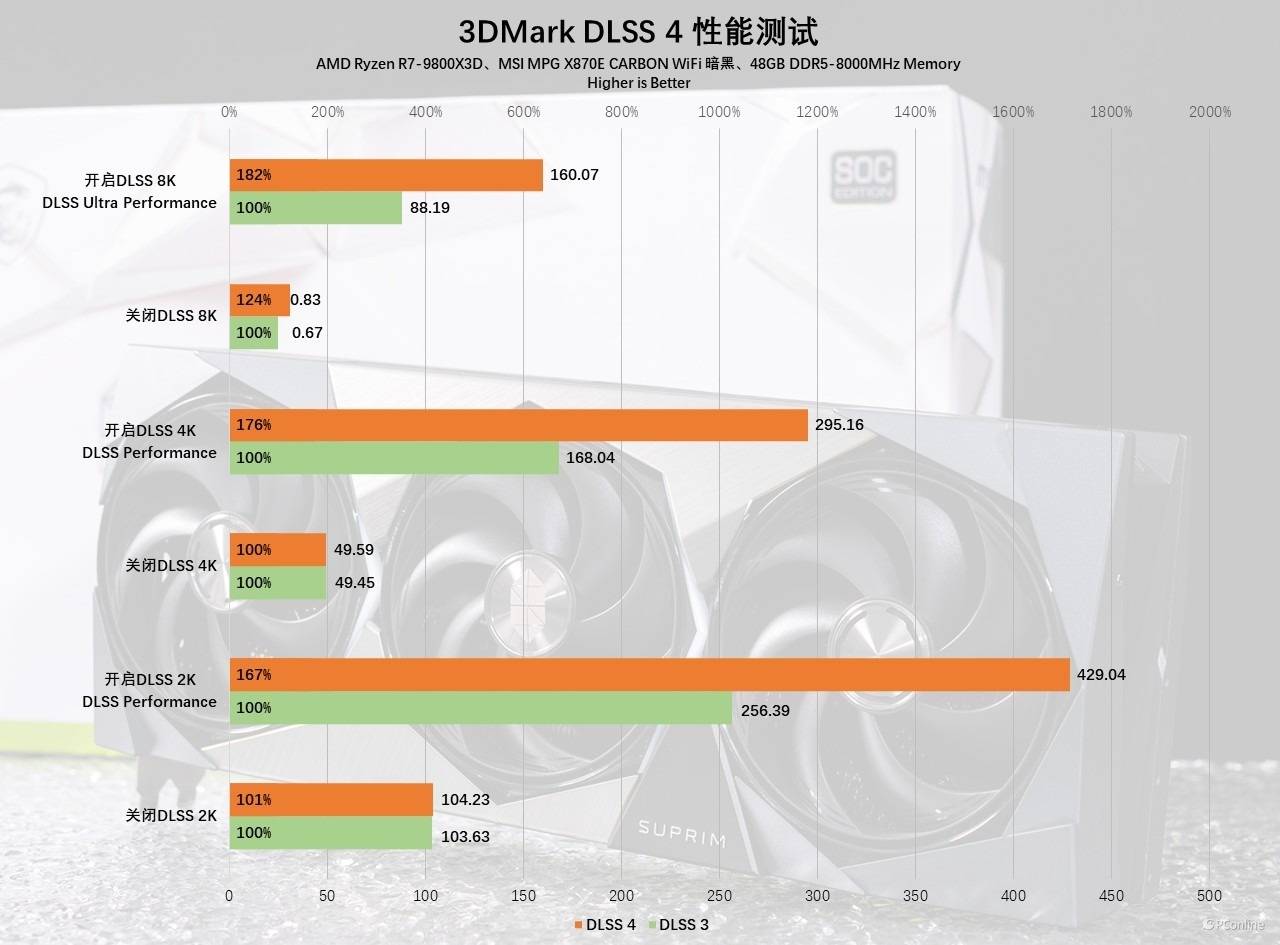
简单介绍完,我们再看看DLSS 4的理论表现如何,还是经典的3DMark测试。不得不说微星GeForce RTX 5080超龙SOC搭配上DLSS 4后,帧数就跟打了鸡血一样,开关前后的性能简直天壤之别!其中2K分辨率下,开关前后性能差距足足有4倍之多。4K分辨率时帧数差距直接就是6倍,即便是对比DLSS 3的话,帧数也能提升70%以上。最离谱的还要属8K, 微星GeForce RTX 5080超龙SOC在DLSS 4加持下可以做到156 FPS,这已经畅玩爽玩的水准了。
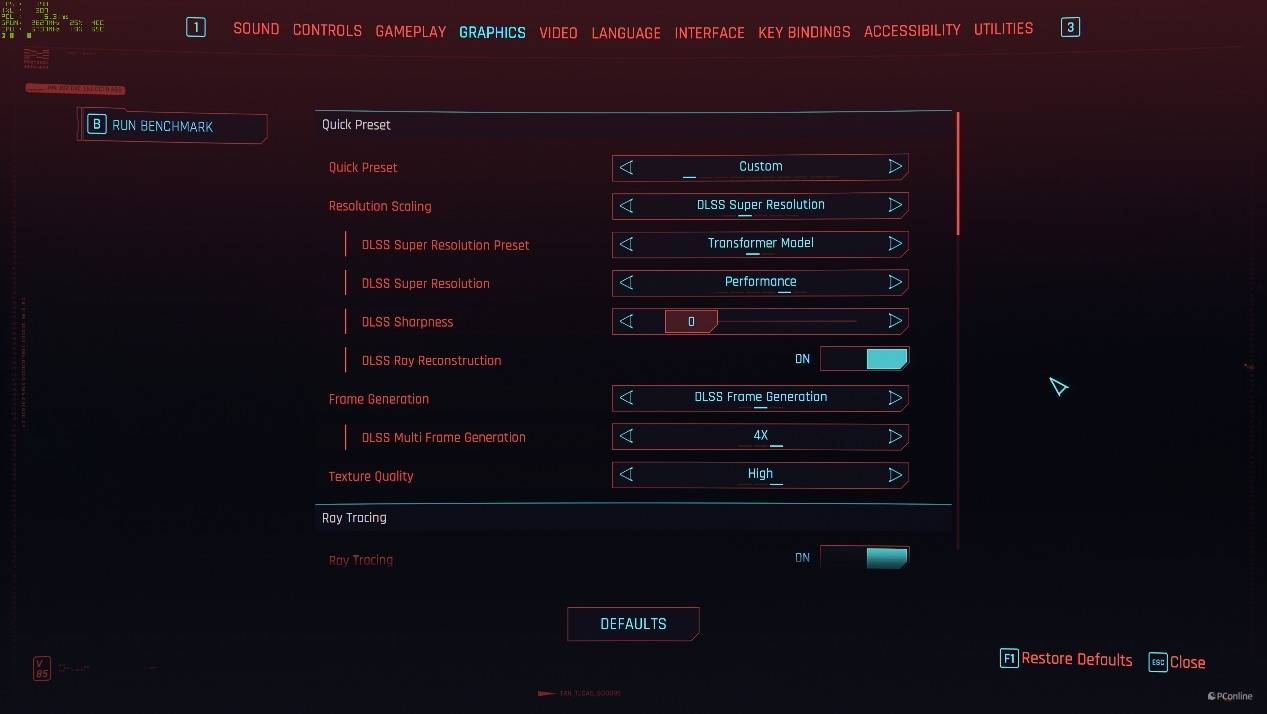
接着我们看看DLSS 4在实际游戏中的表现,率先登场的就是有着“显卡杀手”之称的《赛博朋克2077》,它的设置页面是目前支持DLSS 4游戏中最为丰富一款,除了能够设置DLSS 4的多帧生成外,还可以切换DLSS 4的另一个特性——Transfomer Mode,据说能够让画质更清晰,同时还能改善此前的拖影问题,对玩家可以说是一大利好。
我们直接来一波对比,左侧为Transformer模型,右侧则是原本的CNN模型。从第一个场景来看,Transformer模型能够带来更多的细节。例如左侧图片中的栏杆倒影,这部分表现是比较清晰的,而CNN模型中则几乎不可见。

第二个场景也是能够一眼看出区别的,例如金属门的纹理细节以及砖墙的接缝处,明显是Transformer模型的优化要更好一些。

这个场景的区别主要在于地板细节刻画以及右侧铁栏杆部分,采用Transformer模型的情况下,地板细节更接近真实世界,并且铁栏杆的细节也能更好的还原。而CNN模型则会丢失比较多的细节,虽然不影响观感,但总有种“失真感”。

不过Transformer模型目前也并非万能,毕竟是由AI生成而来,因此在部分细节上还是有些错误的。例如下方的窗口部分,阳光照射下应该是斑驳的光影,比较正确显示的应该是CNN模型中的样式。整体来看,现在Transformer模型瑕不掩瑜,大幅改善的画面细节能够给玩家带来更精致的游戏展现。

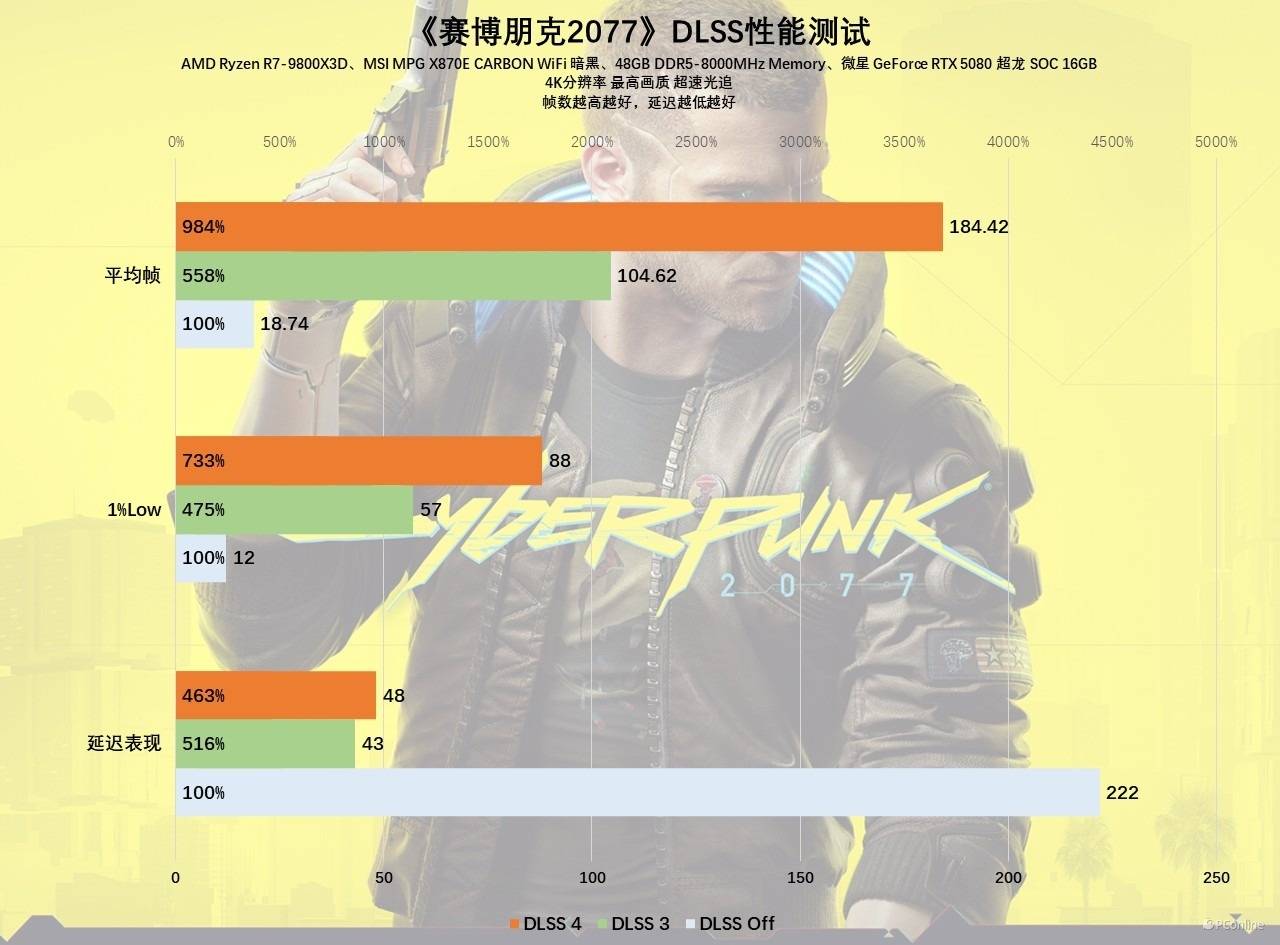
见识完Transformer模型的魅力以后,我们再来看DLSS 4的性能表现,毕竟是“显卡杀手”,对显卡的压力确实不一般,在最高画质+路径追踪的情况下,微星GeForce RTX 5080超龙SOC只能跑18.74 FPS,完全不可玩。开启DLSS 3以后,游戏帧数为104.62 FPS,体感已经非常流畅了。开启DLSS 4以后,微星GeForce RTX 5080超龙SOC能够做到184.42 FPS,对比原生分辨率,性能足足提升了8.8倍。1%Low就更离谱了,几乎快要追上DLSS 3下的平均帧了,整体游戏体验更佳。
DLSS 4带来的性能提升是有目共睹的,不过也有玩家担心DLSS 4的画质表现如何,这里我们也在游戏中截取了部分画面,第一个场景其实差距不大,肉眼很难分辨出区别。

第二与第三个场景还是能够看出部分细节的,例如第二幅图中的霓虹灯牌,DLSS开至性能档以后,能够看到灯牌与前面三张图有些许差异,不过你得靠细致的对比才能看出。实际游戏过程中很难发现,基本不影响观感。

总的来说,DLSS对画质的影响没有玩家想象中那么大,甚至于在纹理细节上能够不输或超越原生分辨率。如果你是敏感型玩家,那建议可以开至平衡档,在画面质量和帧率之间能够做到很好的平衡。如果你是追求超高帧率,那性能档也绝对可用,细节保留也不错,不对比基本看不出,同时帧率还能进一步提高。

我们测试的第二款DLSS 4游戏是《霍格沃兹之遗》,支持DLSS 4技术以后可以在设置看到帧生成部分多了一些选择,其中×2则是原本DLSS 3的帧生成,而×4则是RTX 50系独有的多帧生成功能,另外你也可以选择插2帧的方式,也就是所谓的×3选项。
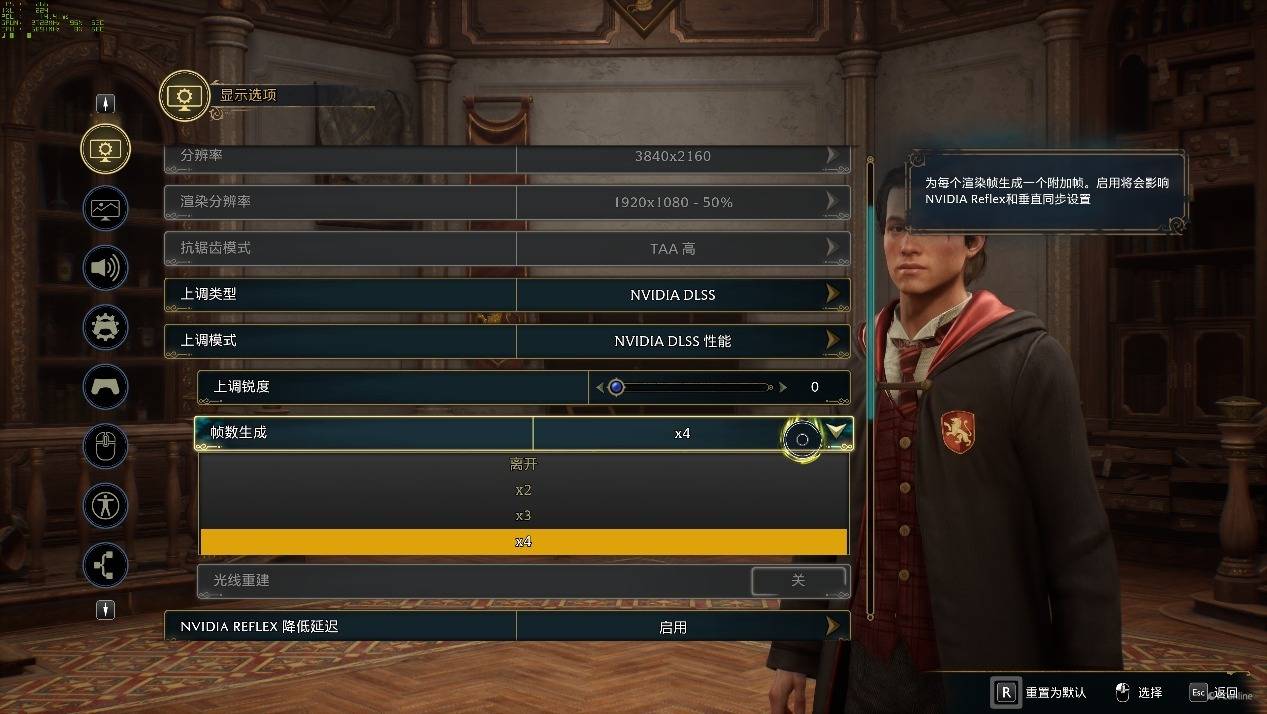
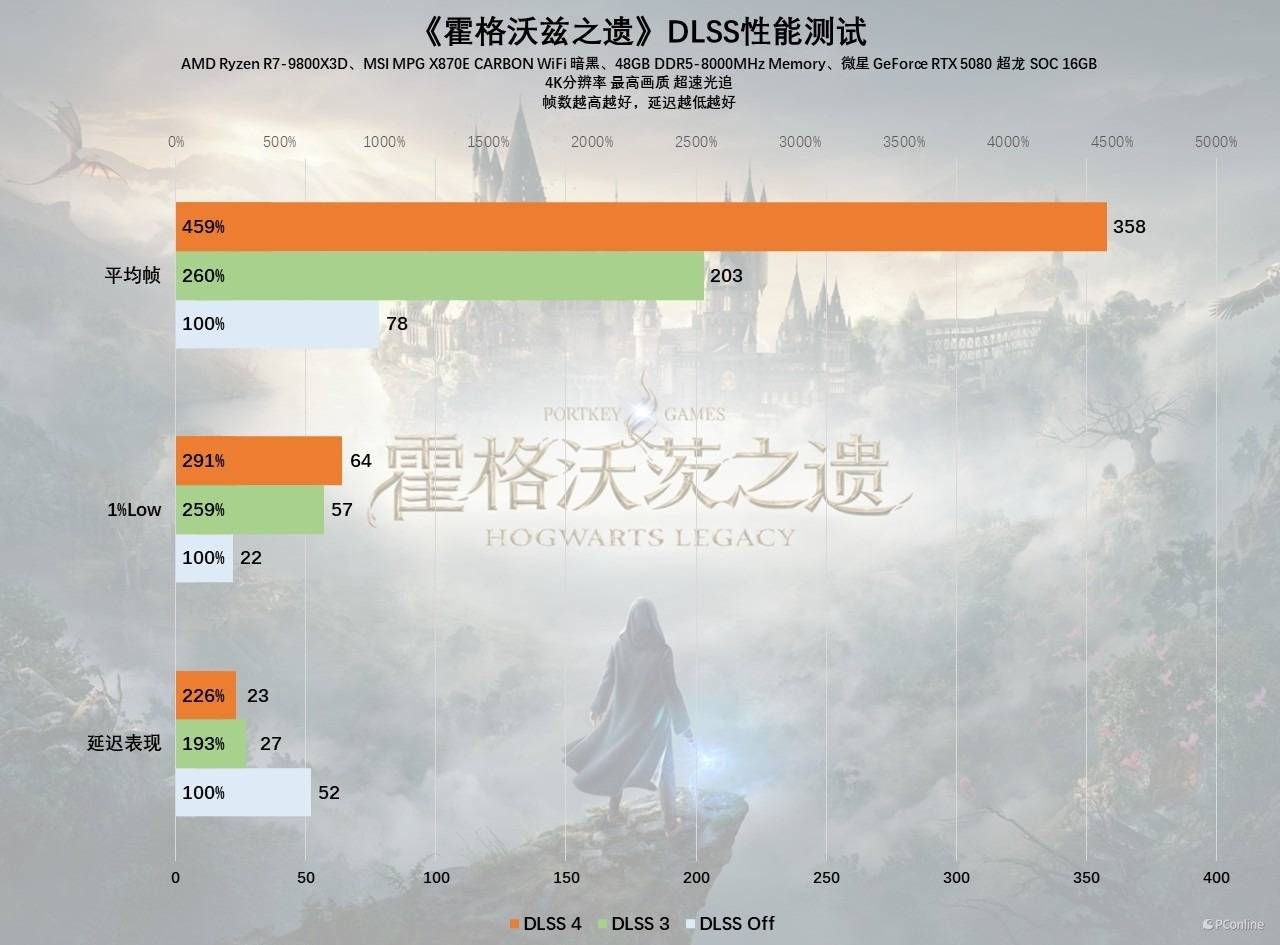
实际测试过程中,我们发现《霍格沃兹之遗》这款游戏优化还是不错的,4K分辨率画质光追均设置最高的情况下,微星GeForce RTX 5080超龙SOC在不开任何超分的情况下,平均帧为78 FPS。如果开启DLSS 3性能档,此时帧数已经能够做到203 FPS了,体验已经相当丝滑了。开启DLSS 4以后,帧数可以进一步提升至358 FPS,对比原生4K时,性能提升了约4.5倍以上。同时实际游戏过程中,无论是1%Low还是延迟都不错,特别是延迟,相比原生分辨率还要低不少,跟手感更好。
第三款游戏我们测试的是《星球大战》,一样你能在设置中看到其帧生成功能已经支持×4的选项,也就是DLSS 4多帧生成功能。
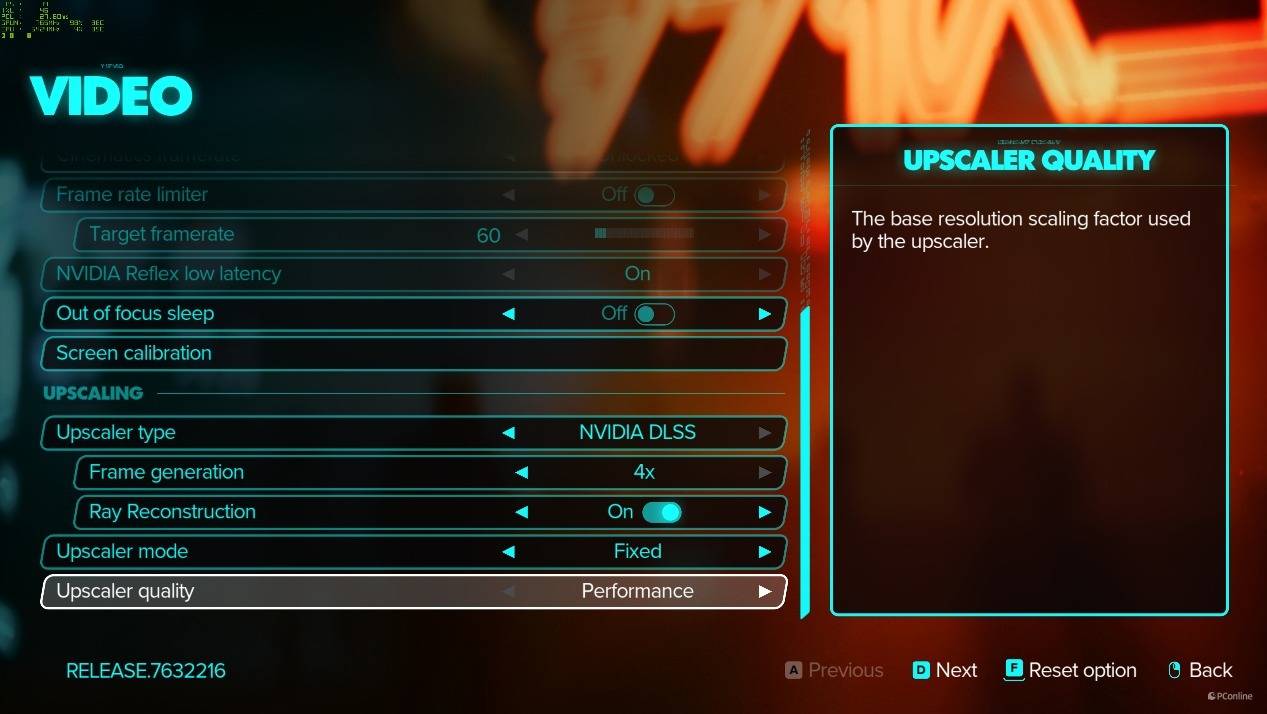
实测DLSS 4在这类优化欠佳的游戏中确实大有用处,在4K原生分辨率下,微星GeForce RTX 5080超龙SOC的平均帧仅有20 FPS,延迟也是高得吓人,游玩堪称PPT。而开启DLSS 4性能档以后,游戏平均帧直接暴增至170 FPS,游戏体验如德芙般丝滑,对比原生4K的表现,足足有8.5倍左右的提升。即便是对比DLSS 3的95 FPS,那也是接近翻倍的性能提升。
最后一款游戏是我们的老熟人《漫威争锋》,这款游戏在RTX 50系显卡首发之时,它还没有完全适配DLSS 4,玩家想要体验多帧生成功能还需要依靠NVIDIA App的DLSS 4优设功能。不过现在《漫威争锋》也正式支持DLSS 4了,与上面的游戏一样,玩家在游戏设置中就能直接开启,并且提供了2x、3x以及4x选项,玩家可以随意选择是插一帧、插两帧还是插三帧。
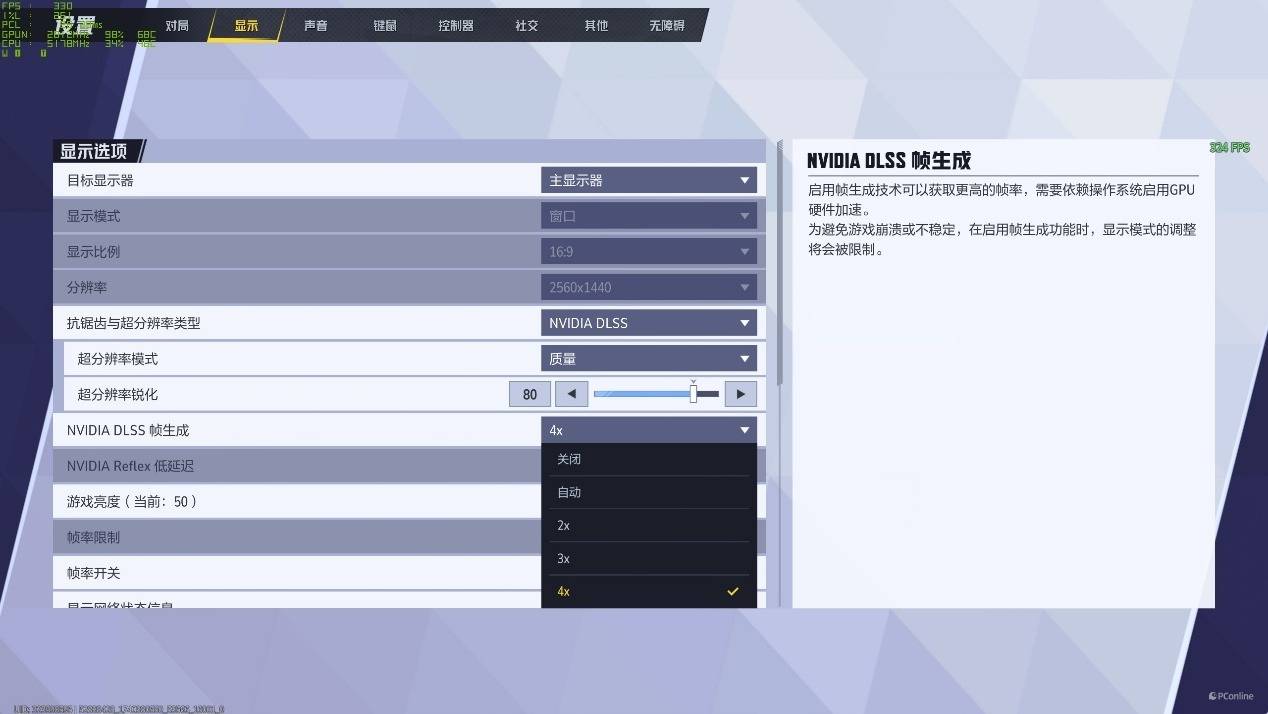
实测微星GeForce RTX 5080超龙SOC在4K全高设置下,不开超分,帧数为74 FPS,流畅玩是没问题了,不过想要追求高刷体验就要开启DLSS 3了,开启后帧数可以达到190 FPS,相比原生分辨率已经提升了一倍以上,如果再开启DLSS 4多帧生成,性能对比原生分辨率直接提升4倍以上,327 FPS的表现妥妥的电竞3A。同时延迟表现也非常出色,原生分辨率下,其延迟为26ms,而开启DLSS 4以后,延迟甚至能够降低至23ms,游戏会更加跟手,体感更佳。

当然,如果你想玩的游戏还不支持DLSS 4,那也不用担心,NVIDIA App还提供DLSS 4优设功能,说人话就是能够让游戏强开DLSS 4,像此前的《漫威争锋》,在未更新前,玩家可以直接在NVIDIA App中简单设置,就能将帧生成调至“4×”,一键实现多帧生成。目前也有不少游戏支持DLSS 4优设功能,感兴趣的玩家可以前往体验。

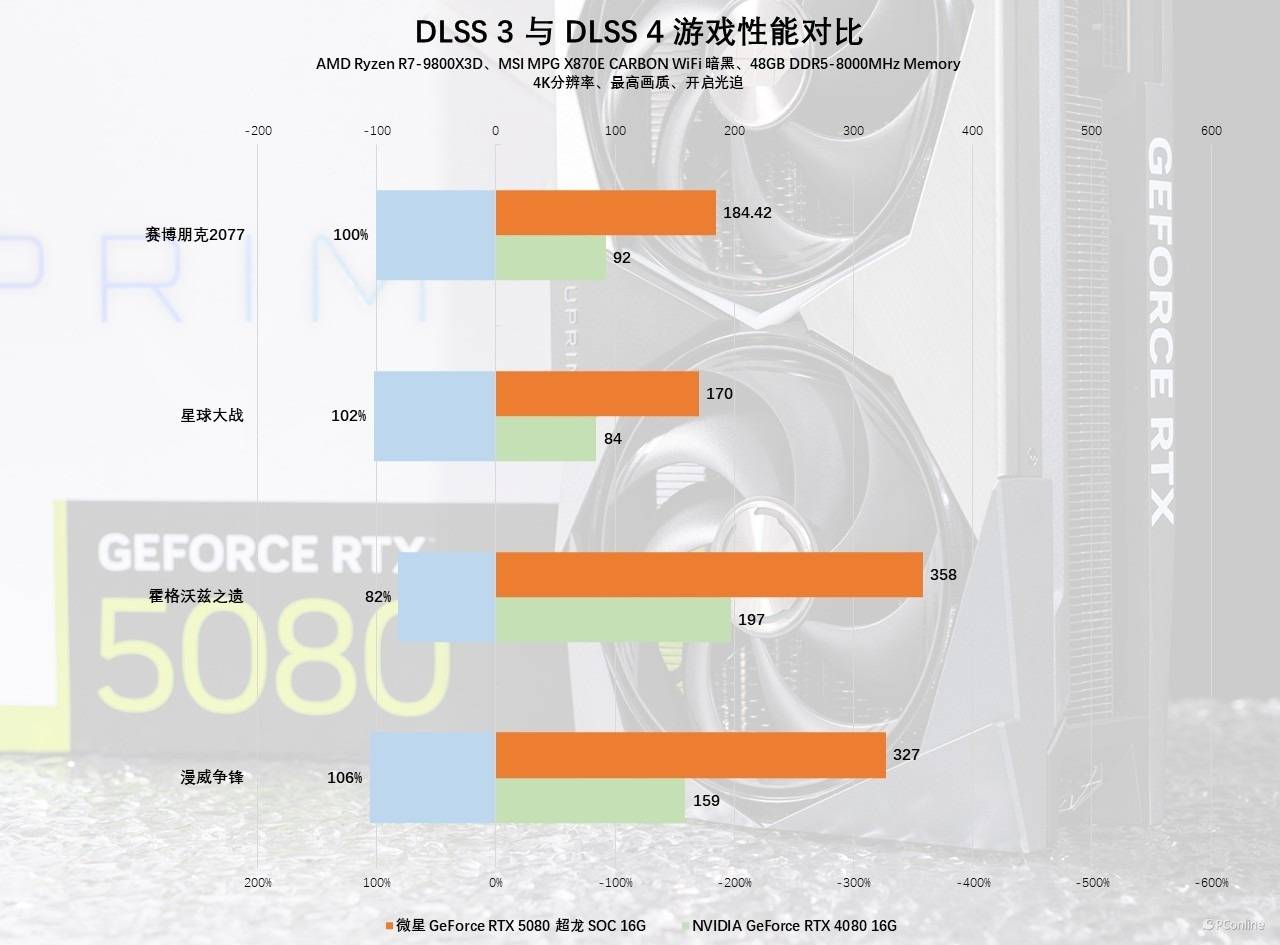
DLSS 4多帧生成功能的问世,毫无疑问为玩家带来了前所未有的游戏体验升级。与上一代RTX 40系的DLSS 3帧生成功能相比,它再次实现了帧数的惊人飞跃。在相同的画质设置下,微星GeForce RTX 5080超龙SOC的表现远远超越了RTX 4080。实际测试中,在上述四款游戏里,开启DLSS 4的微星GeForce RTX 5080超龙SOC,帧数几乎是RTX 4080的两倍!而且,这一显著提升并非单纯依靠硬件堆砌,而是得益于技术的创新与突破,还是非常惊喜的。
另外,值得一提的是,与DLSS 4一起到来的还有全新的NVIDIA Reflex 2技术。延迟一直是电竞中绕不开的话题,玩家的每个动作都会经过复杂的计算,再在屏幕上渲染,这其中的每一步都会增加延迟。虽然延迟往往只有几十毫秒,但是你却能明显的感觉到游戏的不流畅、卡顿。

为了尽可能的降低延迟所带来的不良游戏体验,NVIDIA发布了NVIDIA Reflex技术,它可以使GPU和CPU同步,确保最佳响应速度和低系统延迟。目前NVIDIA Reflex已集成到超过100款游戏中,可以将PC延迟降低50%。

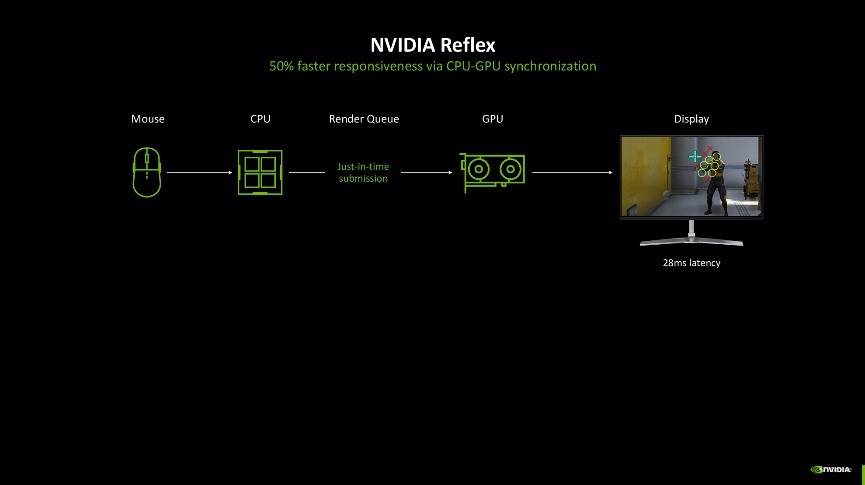
而GeForce RTX 50系显卡再度升级,带来了NVIDIA Reflex 2技术。它结合了Reflex低延迟模式与frame Warp技术。它可以把最新的鼠标输入指令同步给渲染帧,及时更新渲染的游戏帧并在渲染帧被发送到显示器之前获取最新的鼠标信息,通过刷新渲染的游戏帧以进一步减少延迟,将PC延迟进一步降低多达75%。
另外,frame Warp的加入,能够进一步将延迟降低。当一个帧被GPU渲染时,CPU会根据最新鼠标或手柄输入计算工作流中下一帧的视角位置。frame Warp从CPU采样新的视角位置,然后将GPU刚才渲染的帧扭转到最新的视角位置。在渲染帧被发送到显示器之前,在尽可能最新的时间进行扭转操作,确保屏幕上反映最新鼠标输入。
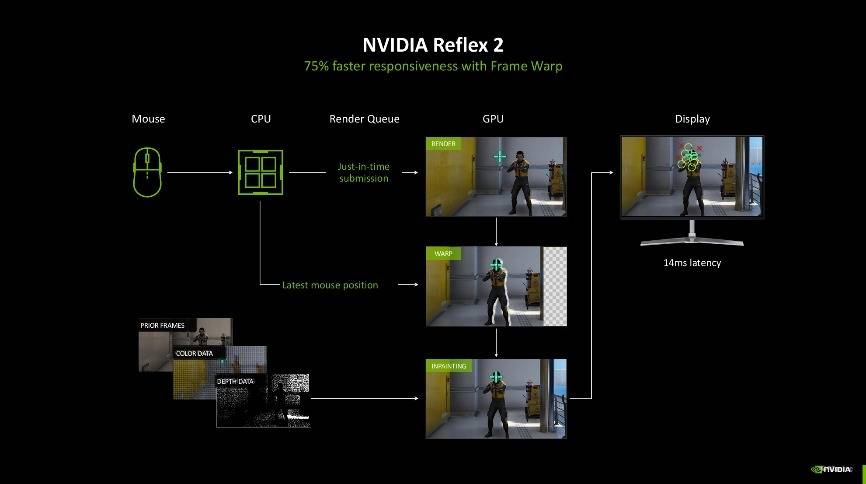
而当frame Warp转移游戏像素时,图像中可能会产生缝隙撕裂、镜头位置的变化会让游戏场景中显示新的部分。NVIDIA则开发了一种优化了延迟的预测渲染算法,该算法使用来自先前帧的视角、颜色和深度数据,对这些撕裂空白的像素进行准确的图像修复。玩家可以通过更新的视角看到没有撕裂的渲染帧,并降低了改变游戏内视角位置而产生的延迟。说人话就是现在NVIDIA Reflex 2还可以根据上一帧的信息去脑补一些空白的像素,有种无中生有但你又看不出来的感觉。
首发支持NVIDIA Reflex 2技术的游戏是《THE FINALS》以及《无畏契约》,后续我们也会第一时间带给大家该技术的详细评测。
游戏性能测试
DLSS 4非常“逆天”,能够带来极致的帧数表现,不过这也需要厂商对DLSS 4进行适配,考虑到目前不是所有的游戏都已经支持DLSS 4,因此下面我们要测试的是常规的游戏以及支持DLSS 3的游戏性能。
还是老样子,先跑3DMark的DLSS 3性能测试。微星GeForce RTX 5080超龙SOC在2K分辨率下,对比RTX 4080或RTX 4080 SUPER,性能提升幅度大概在27%左右,4K分辨率下,开启DLSS 3以后性能领先也基本维持在25%,考虑到三张显卡的CUDA核心几乎没有差距,只能说老黄确实是有点东西,单是凭借Blackwell架构就让性能再次起飞。

实际游戏表现又如何呢?这里我们选取了11款游戏进行测试,包含光追及光栅性能方面的测试,而游戏画质方面均全部选择最高画质,光追设定部分,如有则采用最高。
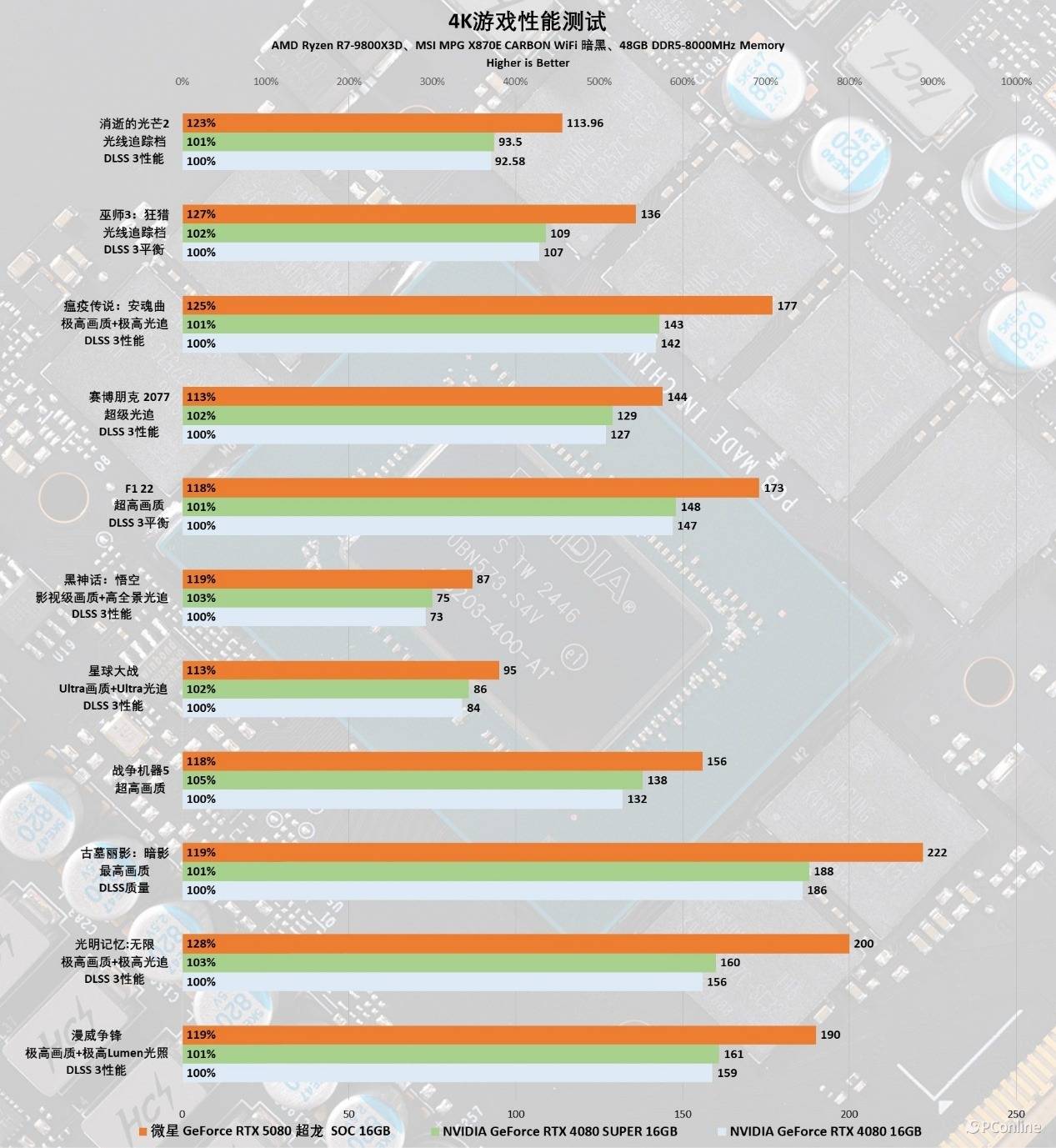
实测4K分辨率下,微星GeForce RTX 5080超龙SOC应对绝大多数游戏都轻轻松松,特别是在DLSS的加持下,满足4K@144Hz电竞没有问题,即便是全高设置的《黑神话:悟空》,这款显卡也能有87 FPS的表现,基本碰到了高刷的门槛,后续如果有DLSS 4想必帧数提升会更加迅猛。具体到性能上,在这么多款游戏里,微星GeForce RTX 5080超龙SOC整体比RTX 4080 SUPER强约20%左右,如果对比RTX 4080的话,性能领先幅度则可以扩大至25%以上。
图像视频创作性能测试
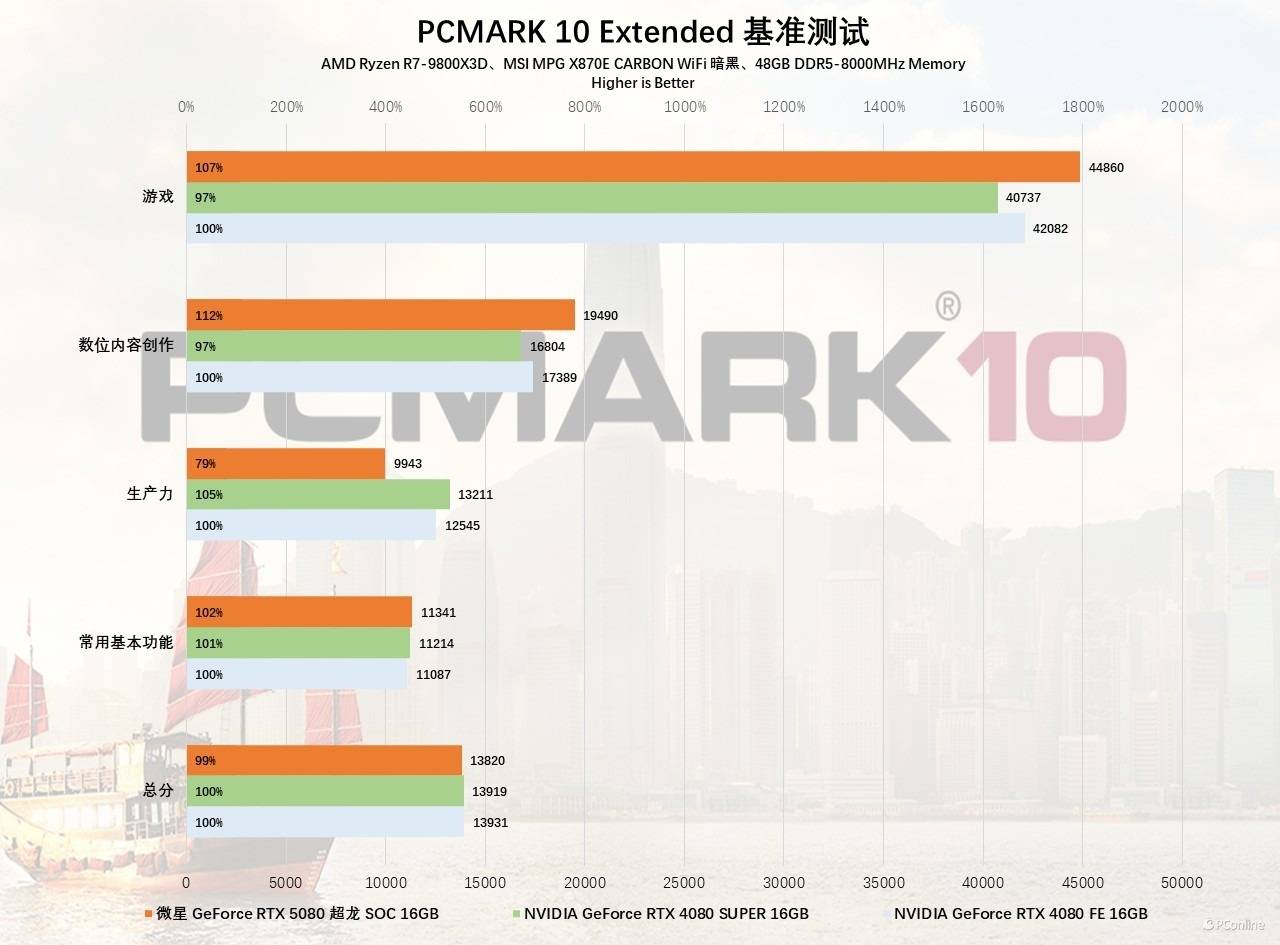
看过了游戏,下面就是专业创作领域的内容了。先给大家伙看一下综合场景的性能表现,在PCMark10 Extended测试,微星GeForce RTX 5080超龙SOC在游戏、数位内容创作方面的表现更佳,基本上要比RTX 4080高10%和15%左右,而生产力方面的成绩则比较低,推测是目前驱动还不完善所致。
办公软件测试中,微星GeForce RTX 5080超龙SOC表现也不错,整体性能可以领先5%左右,其主要领先在Excel、PPT以及Outlook三项。

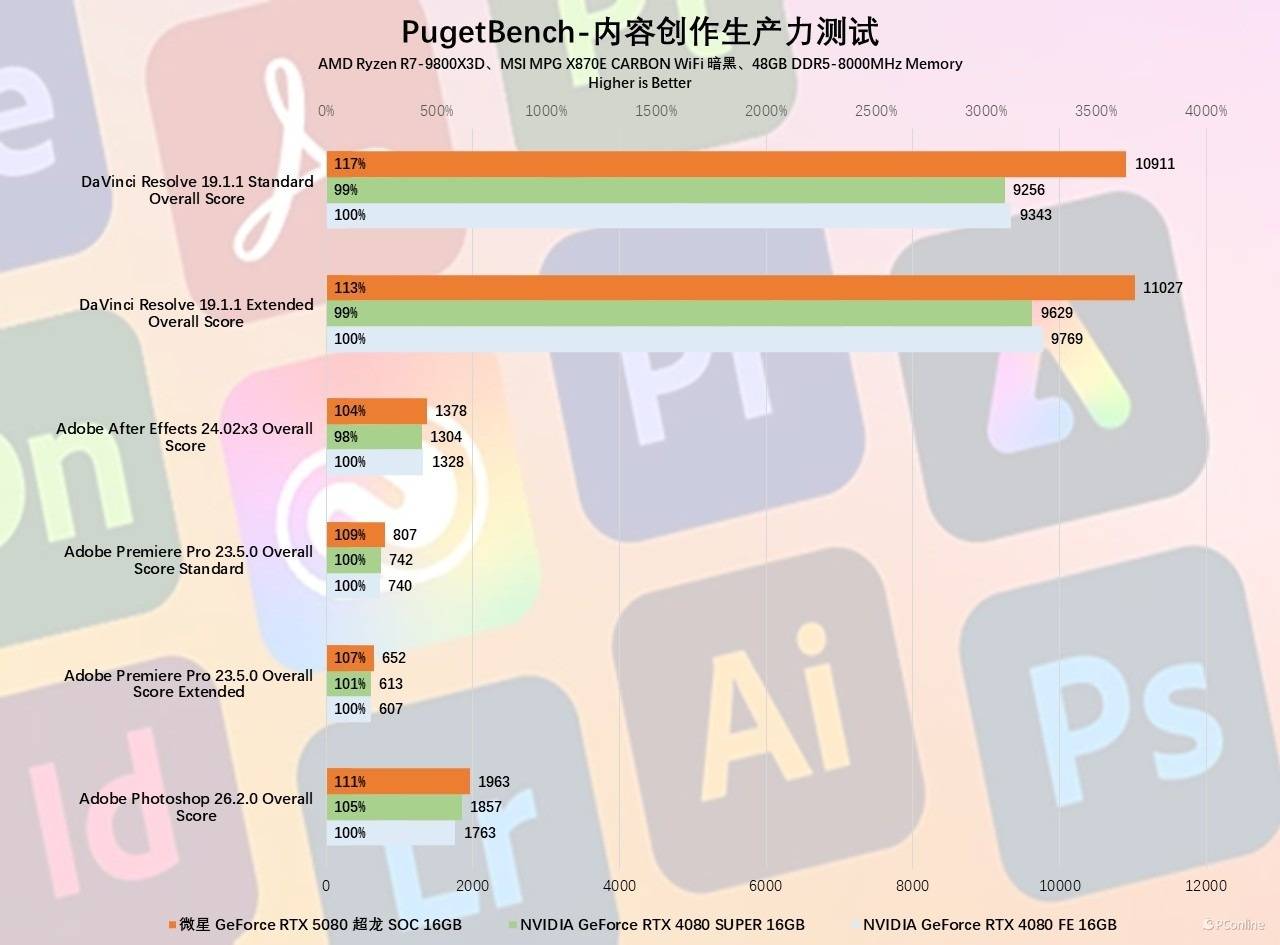
在Adobe以及达芬奇的Benchmark测试里,微星GeForce RTX 5080超龙SOC相比RTX 4080或RTX 4080 SUPER也有提升,不过提升比较大的还是视频编辑部分,究其原因还是这一代RTX 5080对编码器进行了升级,不仅编解码的效率更高,同时支持的格式也更丰富。例如在达芬奇和PR的测试中,微星GeForce RTX 5080超龙SOC领先RTX 4080约7-17%,总体来说就是内容创作的效率更高了。
3D渲染创作性能测试
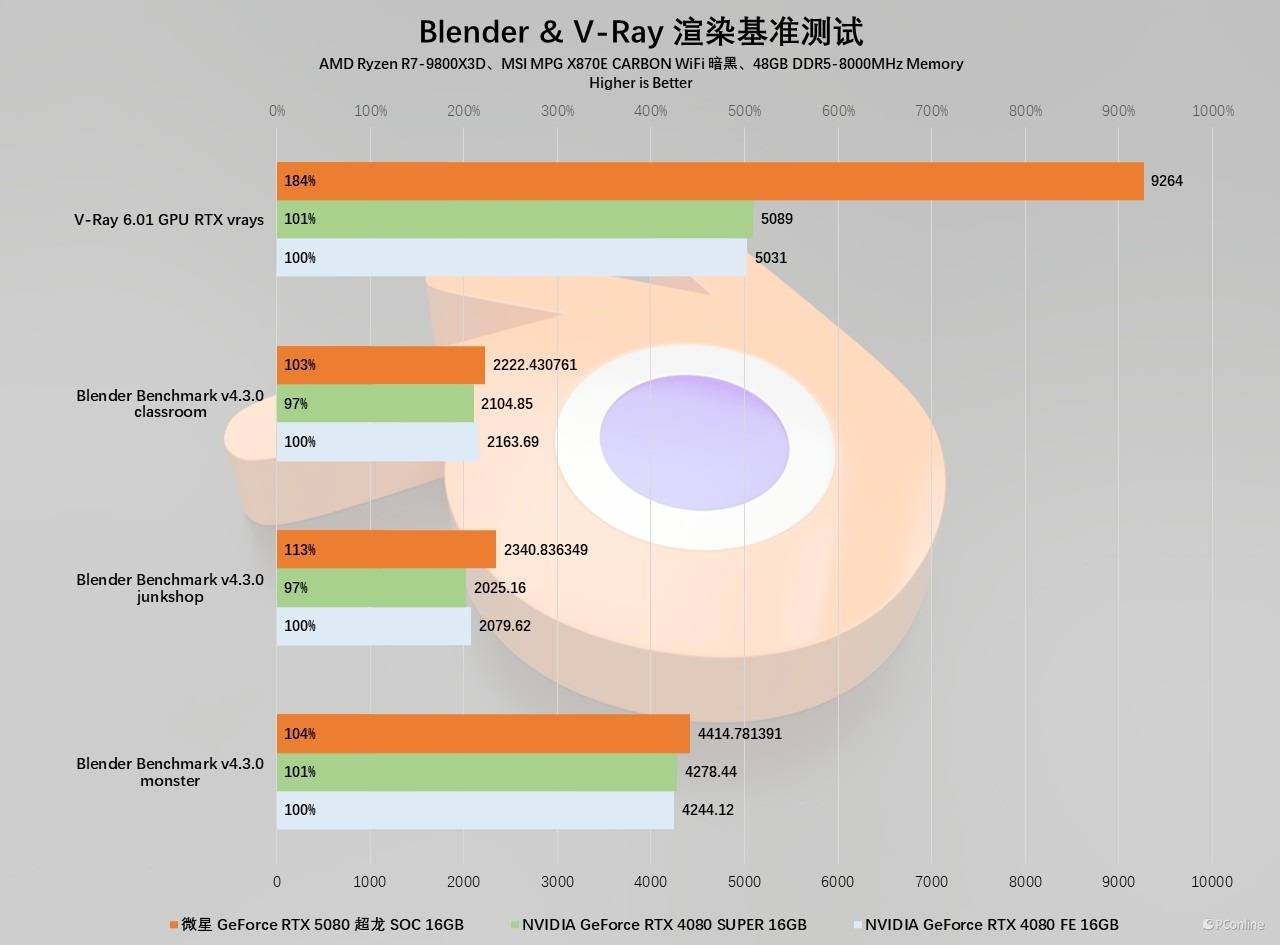
图像视频创作显然对微星GeForce RTX 5080超龙SOC没有压力,让我们看看压力更大的3D渲染以及工业领域软件中,在Blender以及V-Ray两款软件中,微星GeForce RTX 5080超龙SOC的表现可以用夸张来形容,其中前者基本上能领先RTX 4080 SUPER达3%-16%,而后者就离谱了,对比两张40系卡,甚至可以领先84%,几乎是翻倍的性能提升了。
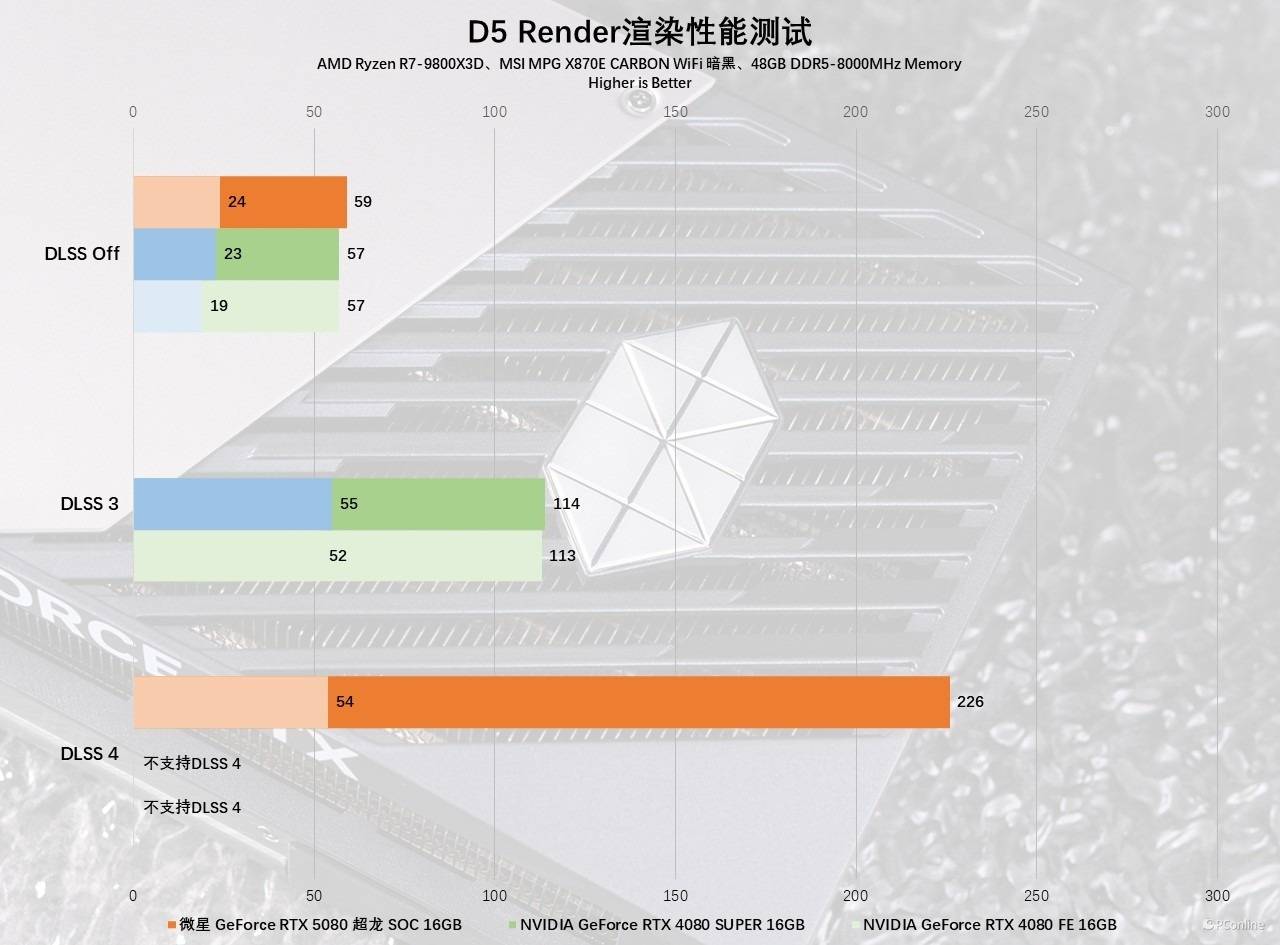
再看看另外一款渲染器,D5 Render是一款基于DXR和光线追踪技术构建的GPU渲染器。正因为其有光线追踪技术,其渲染的画面相当出色。这款软件在RTX 40系显卡测试时支持了DLSS 3帧生成,而现在随着RTX 50系显卡的发布,它也可以通过NVIDIA App的方式支持最新的DLSS 4多帧生成功能。

实测在开启DLSS 4以后,整个渲染预览的界面变得丝滑流畅,帧数基本都在226 FPS附近,而对比不开DLSS时,仅59 FPS的表现来看,性能几乎是提升了4倍以上。即便是面对RTX 40系的DLSS 3,也一点不虚,性能优势也有50%以上。
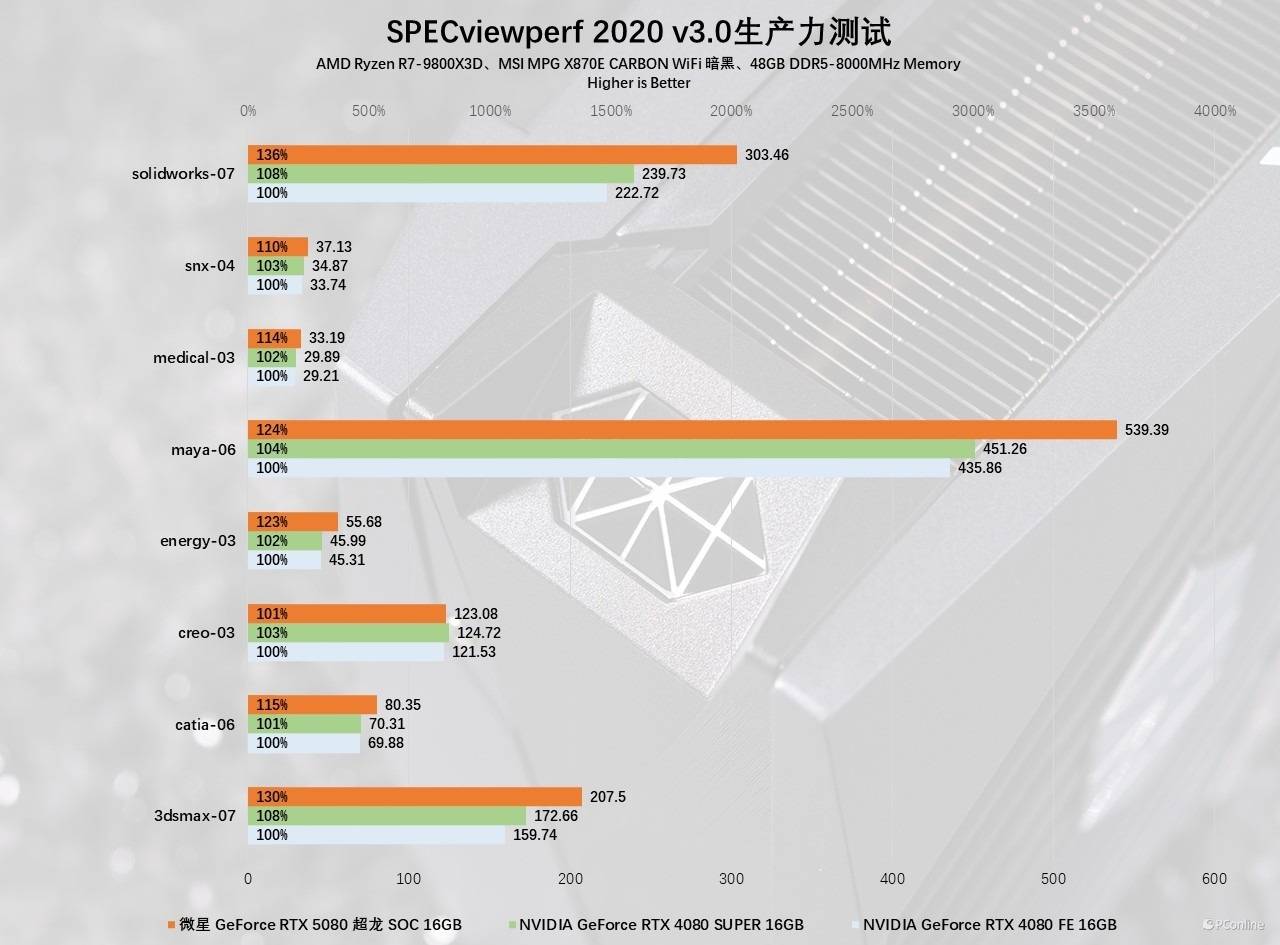
工业领域的表现也是上到了新的高度,其中SPEC2020能够反应显卡的工业能力,在多项测试中微星GeForce RTX 5080超龙SOC,对比RTX 4080平均有30%的提升,而对比RTX 4080 SUPER也在25%左右。
NVIDIA编解码测试
接下来的测试则是介绍RTX 50系显卡的编解码器,GeForce RTX 50系列显卡上换装了第9代NVENC编码器与第6代NVDEC解码器,在视频规格上支持AV1 UHQ(超高画质 AV1)与MV-HEVC(多视角HEVC)编解码。同时由于GeForce RTX 50系列显卡还升级支持DisplayPort 2.1 UHBR20输出,单一通道支持20Gbps带宽,因此用户可以体验到令人惊叹的HDR视觉效果、超高分辨率和更流畅的游戏体验。
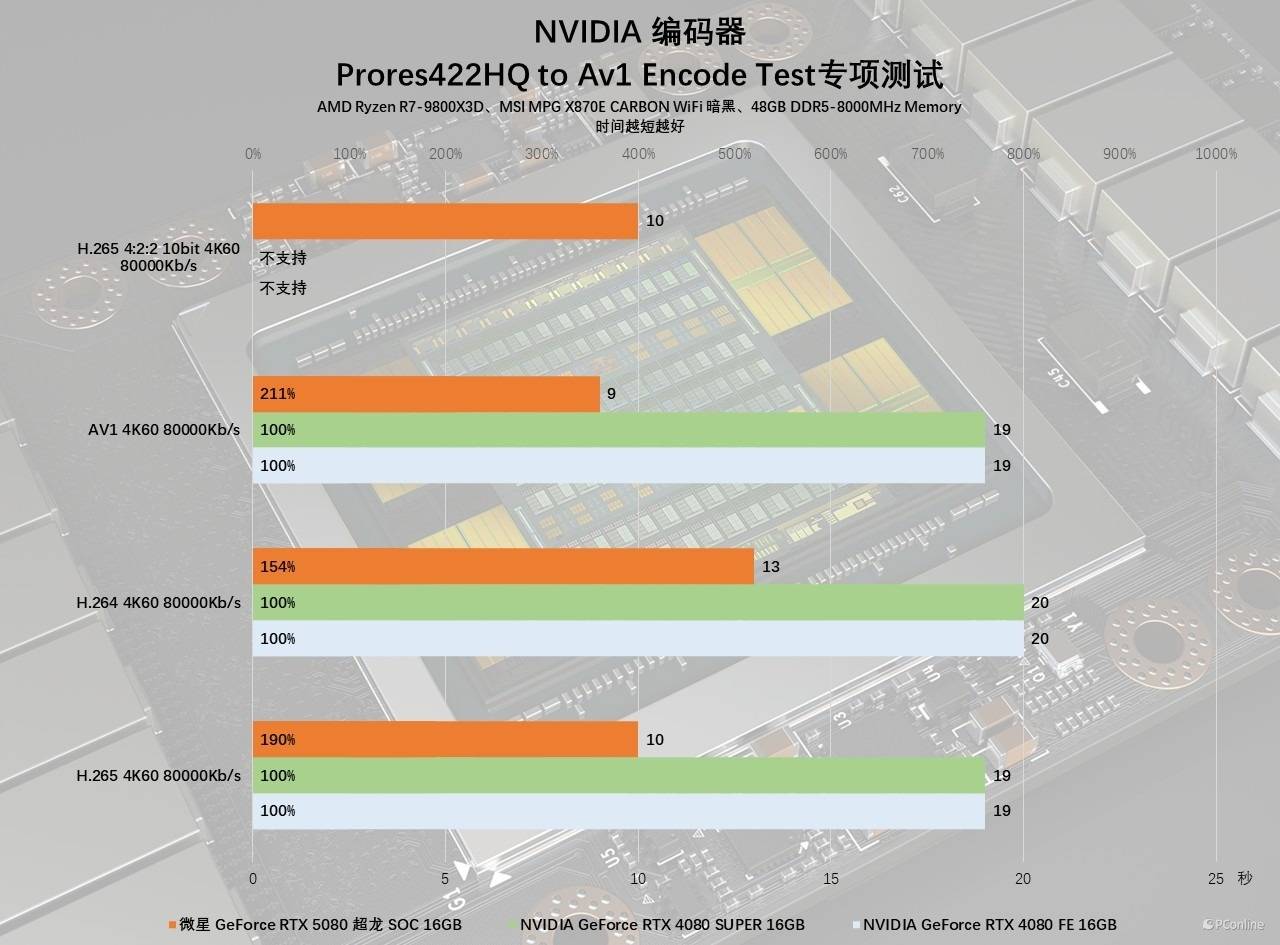
这里我们直接使用NVIDIA提供的4K60片源与工程文件分别测试AV1、H.265以及H.264下的编码导出时间。实测同一段素材下,微星GeForce RTX 5080超龙SOC导出三段视频的时间分别是9秒、10秒以及13秒,效率分别比RTX 4080或RTX 4080 SUPER快了111%、90%以及54%。
同时,我们也对导出的不同格式的视频进行了画质对比,实测AV1编码的视频在画质上与H.265或H.264也没有明显差距,无论是在文字、人像还是建筑等画面里,三者的画质可以说是伯仲之间,如果不特地标注其格式,一般人很难用肉眼分辨出来。随着目前越来越多视频网站、剪辑软件和硬件厂商的推动,未来AV1势必会成为下一个最受欢迎的格式。



值得一提的是,GeForce RTX 50系显卡还能够支持4:2:2色度取样的视频编解码,这将节省CPU的负担,加快创作速度。上面的图表里也可以看到我们的测试成绩,实测导出时间会比上代显卡快不少,毕竟RTX 40系显卡不支持该功能,仅支持4:2:0色度采样,如果一定要4:2:2导出只能靠CPU软解。
4:2:2色度采样的视频文件采用的是YUV颜色格式,与存储红色、绿色和蓝色(RGB)值不同,颜色被存储为亮度Y、蓝差色度U和红差色度V。在这类视频中,视频的完整亮度将被保留,而原始色度信息只保留一半,因此相比4:4:4的视频,其视频帧数据量仅有不到三分之二,而相比4:2:0的视频又能提供两倍的颜色分辨率,因此创作者采用这种格式拍摄,能够在保留更多色彩信息的同时还能减少文件大小和带宽需求。

AI性能测试
AI性能目前也是大家关注的重点,特别是在国产大模型爆火以后,各行各业都开始接入AI,似乎AI成了必选项。RTX 50系显卡也针对AI进行了改进,其中最值得说道的就是其加入了对FP4精度模型加速处理的支持,它相比此前RTX 40系上的FP8精度,能够实现更快的生成速度,同时显存占用也更低。
不信你看,我们用UL Procyon的FLUX.1 AI Image Generation Demo For NVIDIA进行测试。在均使用FP8精度模型时,微星GeForce RTX 5080超龙SOC能够做到13.705s生成一张图,而RTX 4080或RTX 4080 SUPER则要17秒以上;而切换到FP4精度模型后,速度才真正拉开了差距,微星GeForce RTX 5080超龙SOC生成图片的速度能够提升到6.742秒一张,效率翻了一倍不止。而RTX 4080或RTX 4080 SUPER的生成时间则不降反升,两代显卡的性能差距拉大到了3.5倍以上。
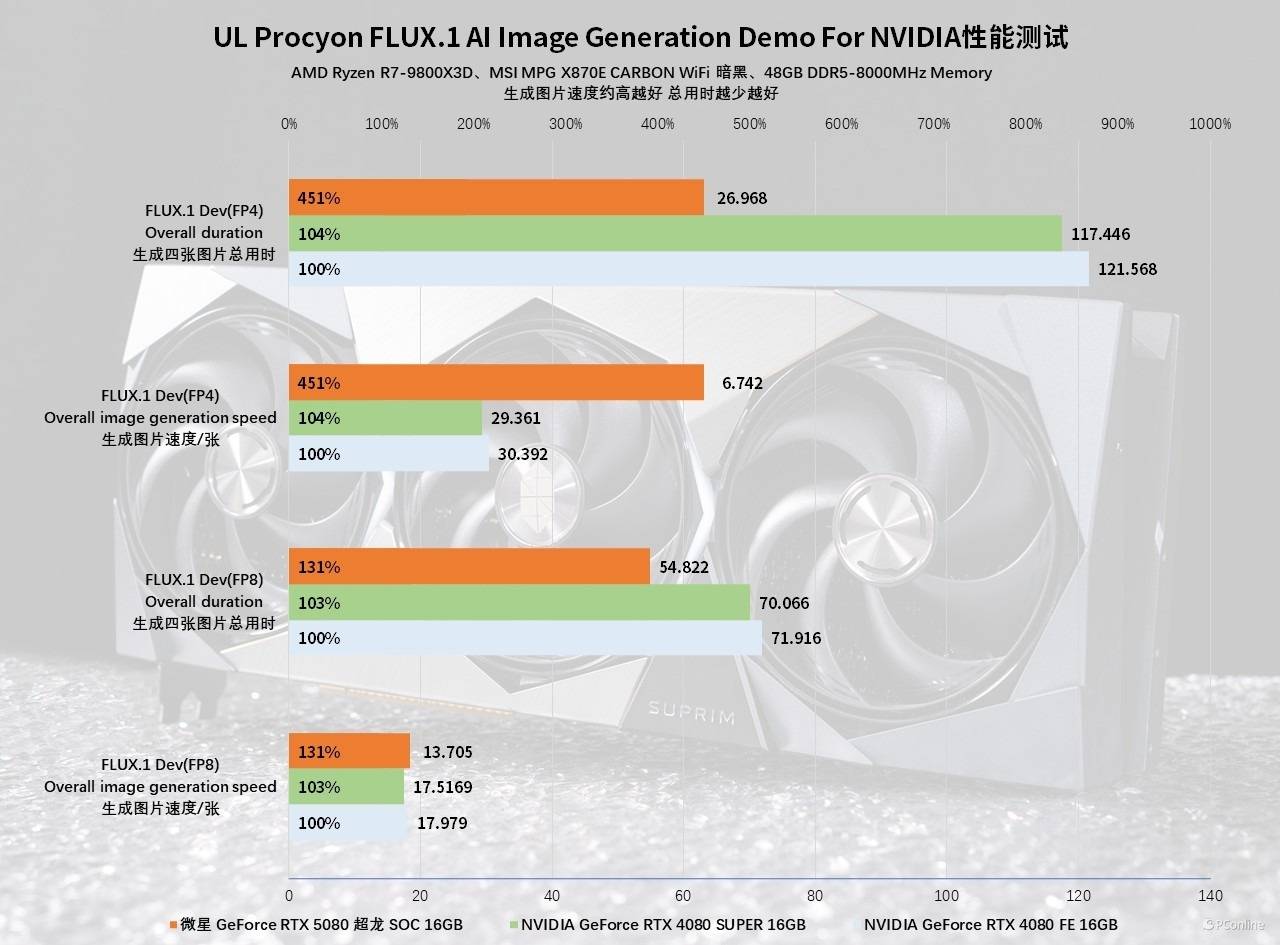
并且FP4精度模型生成的图片也非常能打,从下图就能看出来,其与FP8生成的图片几乎没有区别,无论是对关键词的理解还是图像的质量,都非常有保障。

看过了FP4以及FP8,我们再看看微星GeForce RTX 5080超龙SOC在Stable Diffusion中FP16以及INT8下的表现如何,还是用UL Procyon进行测试,在比较轻松的SD 1.5文生图测试里,无论是采用FP16精度模型还是INT8精度模型,微星GeForce RTX 5080超龙SOC的表现都远超前代显卡,特别是在INT8精度下,生成一张图的速度仅需0.54秒,效率比上代显卡快了48%,已经接近一倍了。而即便是在压力比较大的SDXL中,优势也非常明显,生成一张图的速度为8.439秒,同样领先RTX 4080或RTX 4080 SUPER约1-2秒。

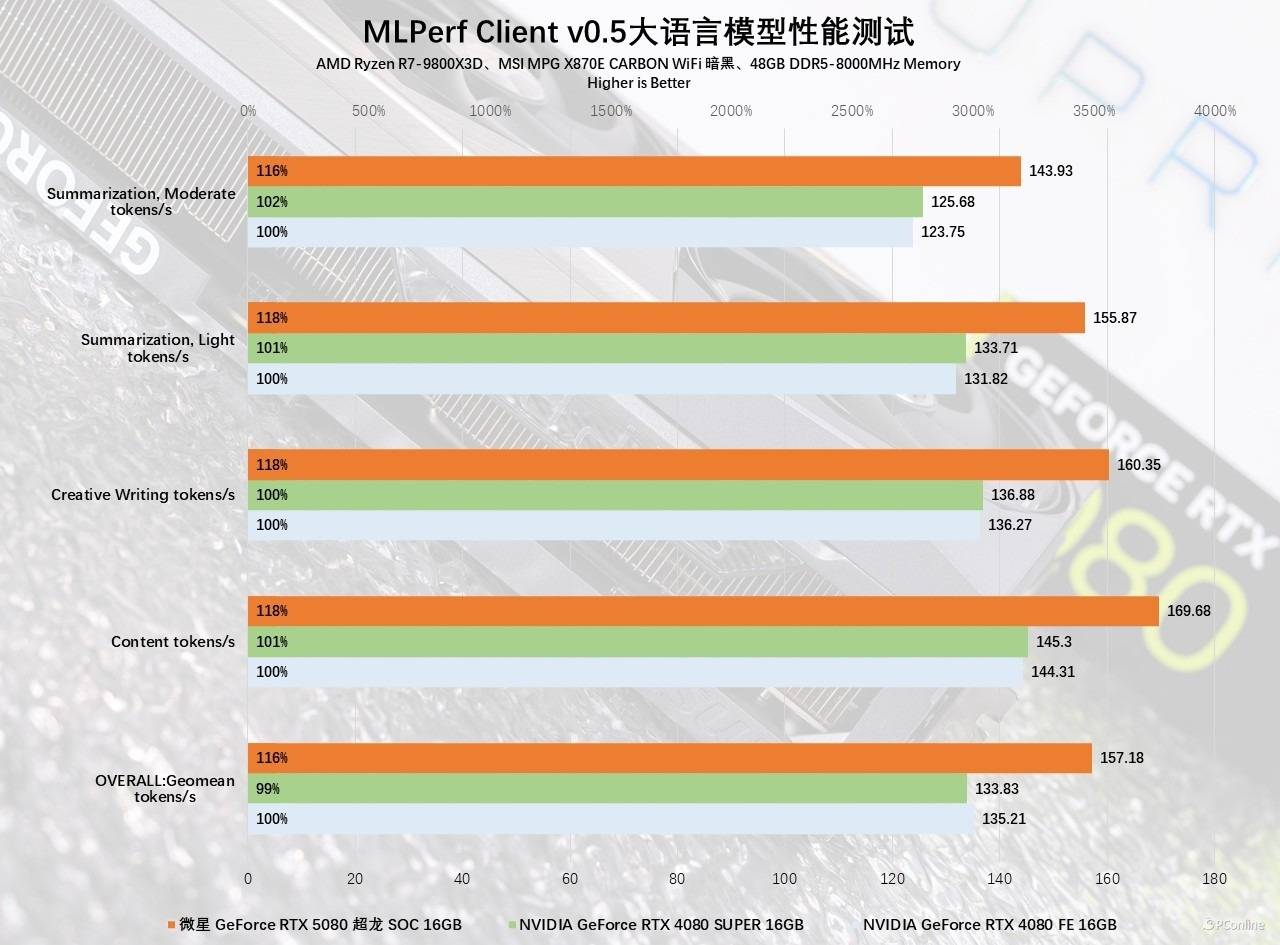
在AI文本生成测试中,微星GeForce RTX 5080超龙SOC在一众大语言模型里同样表现出众,我们用MLPerf Client v0.5大语言模型进行测试,它是基于meta的Llama 2 7B开源LLM打造,涵盖了四项AI任务,分别是内容生成、创意写作以及对两份不同长度文本进行总结摘要。实测新显卡在每一项中都表现出了绝对的统治力,各项测试均遥遥领先,性能提升幅度均在16-18%左右。
接着我们又用UL Procyon的AI Text Generation测试了更多的大语言模型,微星GeForce RTX 5080超龙SOC的优势依旧十分明显,在以Llama 3.1 7B LLM打造的Phi-3.5测试中,新一代显卡取得4522分的成绩,相比RTX 4080提升了16%,相比RTX 4080 SUPER则提升了6%;将参数扩大至13B的Llama 2的测试,微星GeForce RTX 5080超龙SOC也能对答如流,4790分的表现已经离RTX 4090不远了,对比性能的话,则可以领先RTX 4080约28%,领先RTX 4080 SUPER 22%以上。
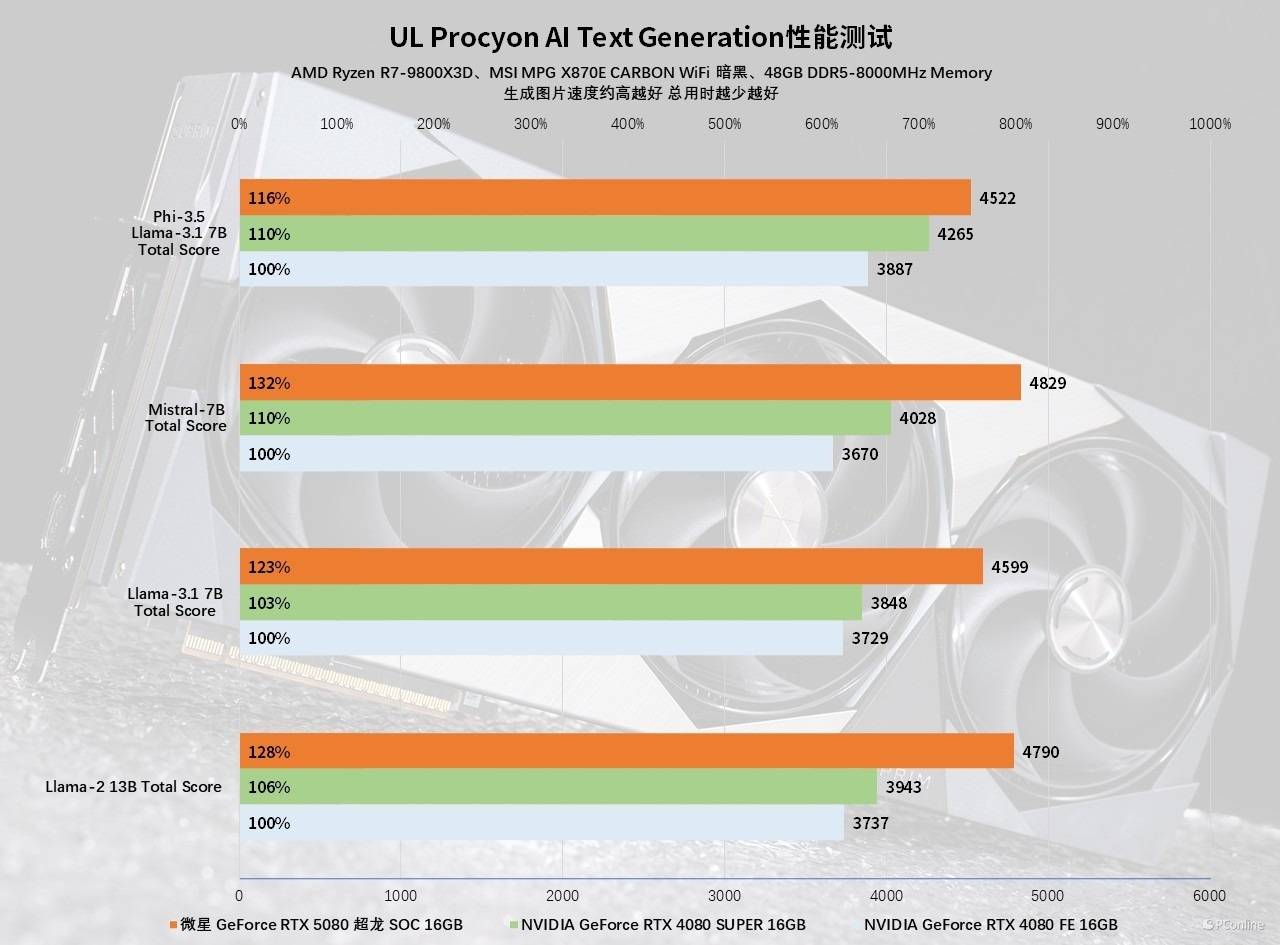
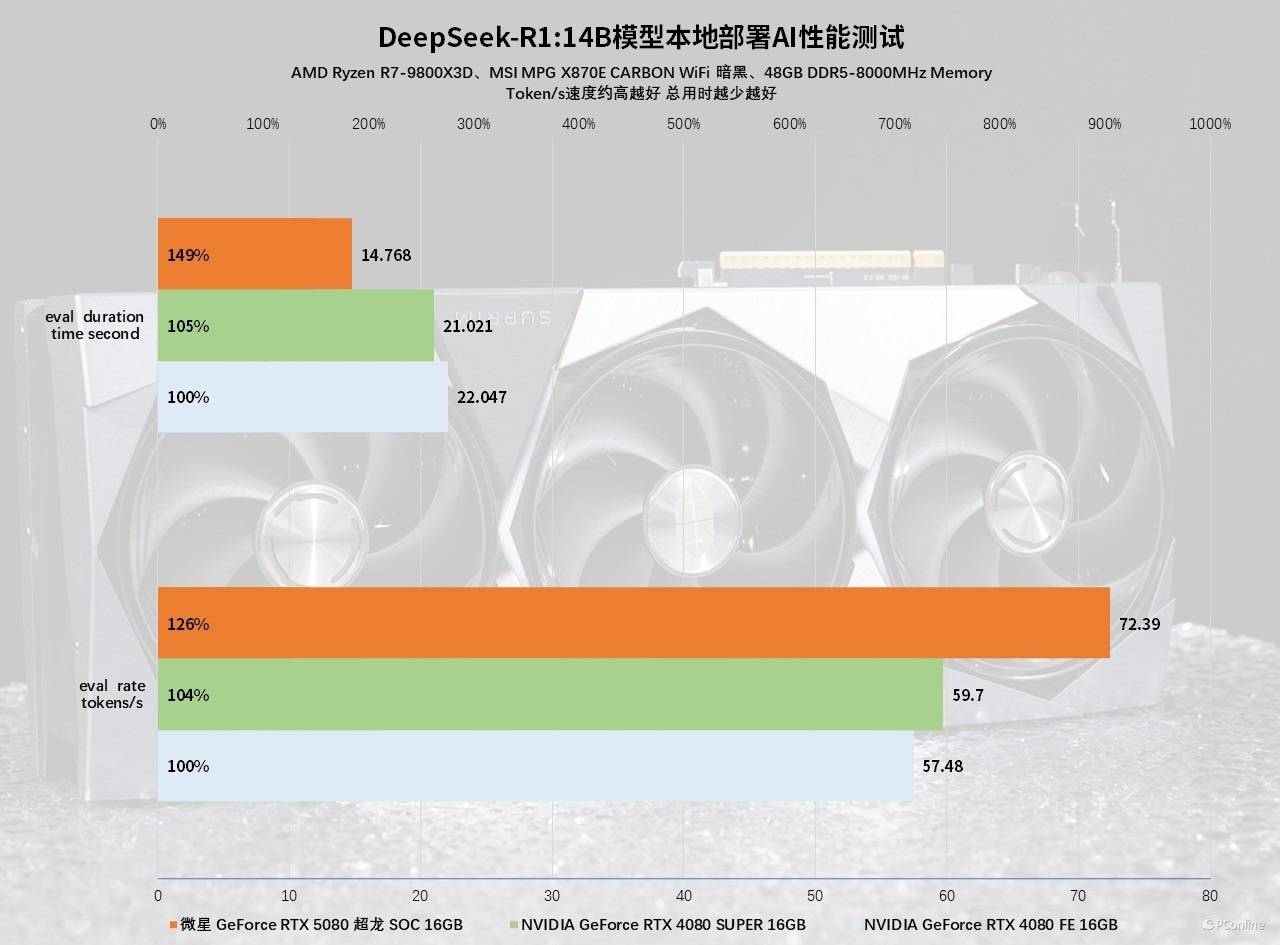
最后,当然少不了我们的国产大模型DeepSeek-R1的测试,现在也是越来越多玩家开始用本地部署去玩转AI了。我们分别用三款显卡本地部署DeepSeek-R1:14B的大模型,让其回答“如何本地部署DeepSeek-R1大模型?”这个问题,实测微星GeForce RTX 5080超龙SOC回答这个问题只需14秒,tokens可以达到72.39 tokens/s。作为对比,即便是RTX 4080 SUPER也要21秒才能回答完成,并且tokens/s为59.7,远远落后于微星GeForce RTX 5080超龙SOC,差距为26%,基本与上面的测试相符。
超频潜力测试
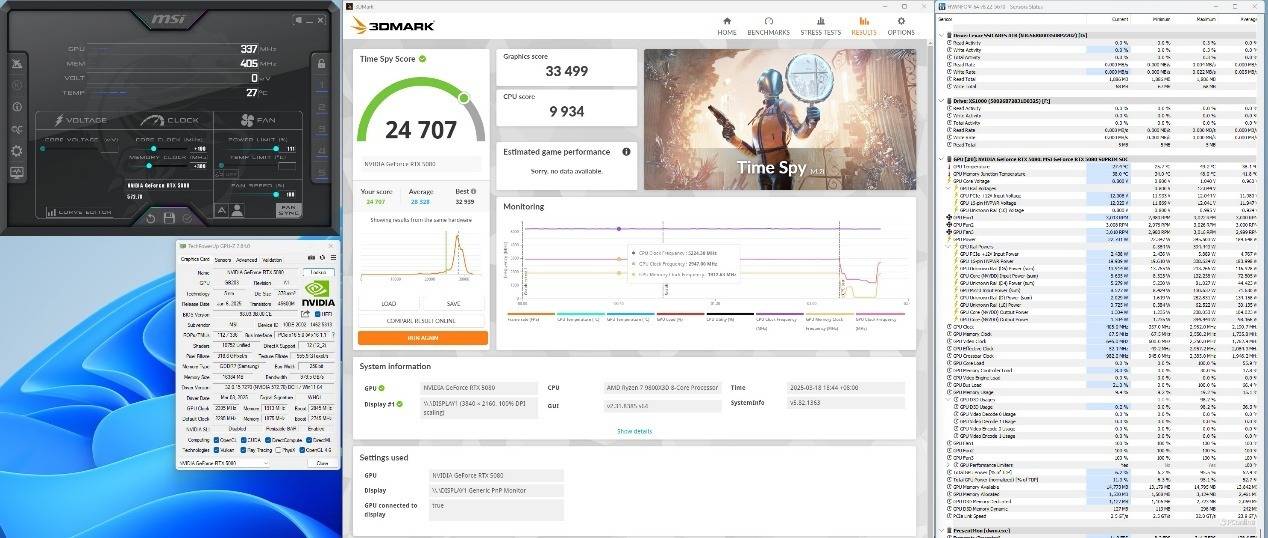
下一项测试超频,作为微星的当家旗舰,又怎么能够不试试它的超频潜力呢?在超频前给大伙回顾一下它默认状态下的成绩,Time Spy得分32386。在显卡设置为GAMING模式、功耗解锁至111%、风扇转速手动拉满的情况下,我们首先给核心加100MHz,显存加300MHz,此时Time Spy得分33499,提升幅度3.4%。
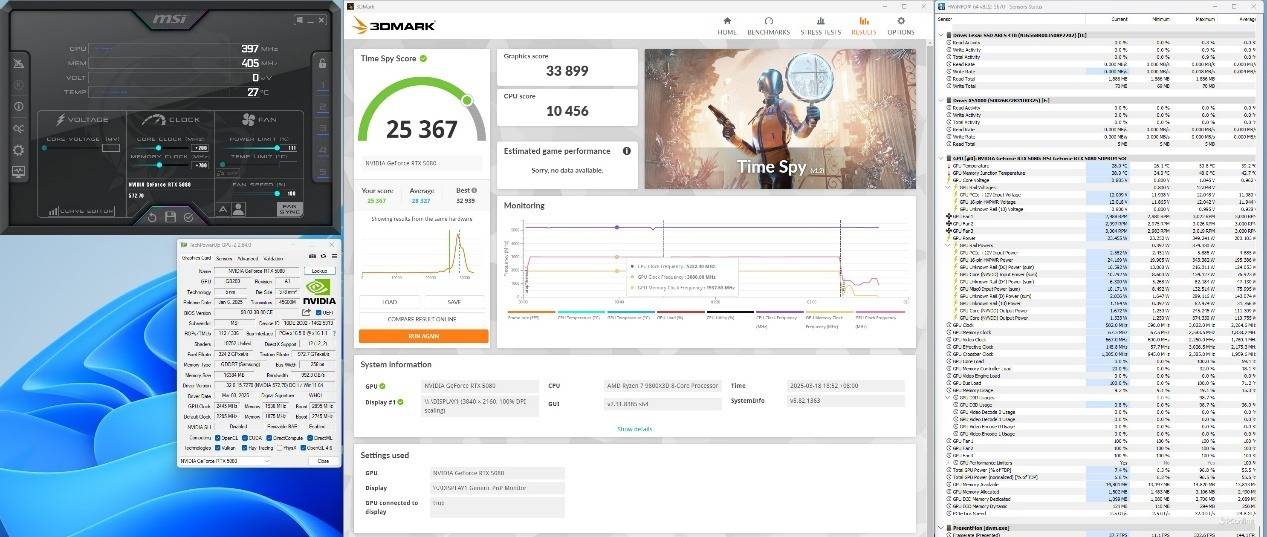
继续增加核心与显存的频率,核心加200MHz,显存加700MHz,Time Spy得分上升至33899。对比默认的分数,提升幅度加至4.7%。
核心加300MHz,显存加2000MHz,Time Spy也能顺利通过测试。并且此时分数有了比较大的提升,来到了35166分,3DMark中软显核心甚至跑到了3142MHz。
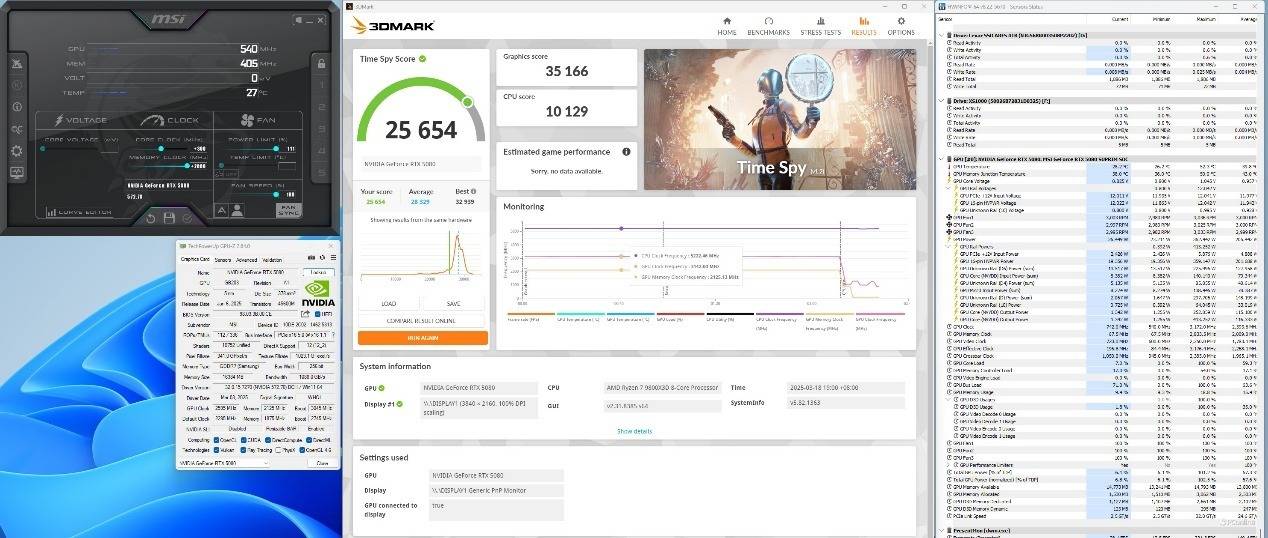
最后,我们成功将微星GeForce RTX 5080超龙SOC的核心加了400MHz,GPU基础频率从2295MHz提升至2695MHz,显存则是加了2000MHz,频率从30Gbps提升至32Gbps。此时Time Spy得分35719分,软显核心频率3240MHz,这个成绩甚至超过了RTX 4090 D,果然微星GeForce RTX 5080超龙SOC名不虚传。

功耗与温度表现
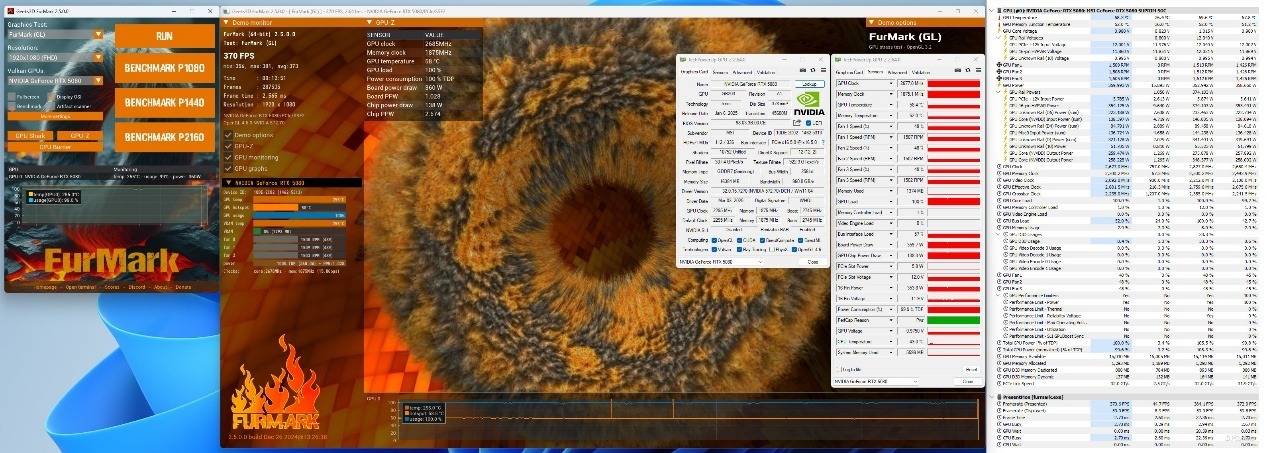
最后一项测试烤机,这也是许多玩家关注的重点。微星GeForce RTX 5080超龙SOC配备了GAMING以及SILENT两种BIOS模式,我们分别进行测试。在GAMING模式下,Furmark烧机10分钟后,得益于微星GeForce RTX 5080超龙SOC出色的设计底蕴,核心温度并不高,仅有58.4度,显存温度更是低至52度,此时显卡的最大功率为359.7W,已经完全顶着TDP的上限了,风扇转速则是1507RPM,表现相当惊人,甚至接近不少水冷卡的表现了。
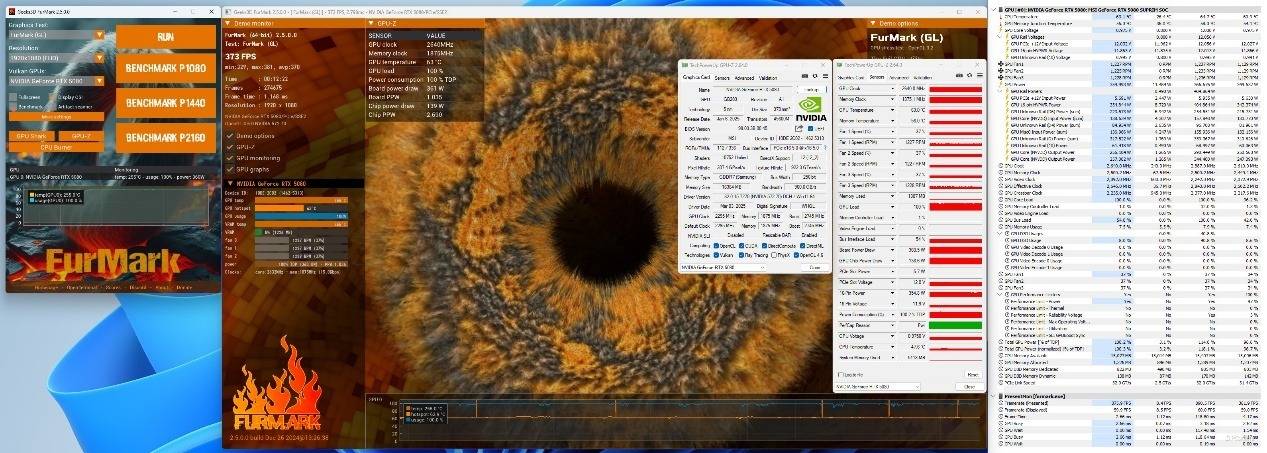
在SILENT模式的设定下,同样是烤机10分钟,核心温度稍有提升,为63℃,显存则是56℃。不过有一说一这个表现也是其他RTX 5080难以企及的高度。SILENT模式还有一个优势就是风扇转速降低了,烤机时为1227RMP,与GAMING模式相差了300RPM,整体噪音表现会更加优秀。
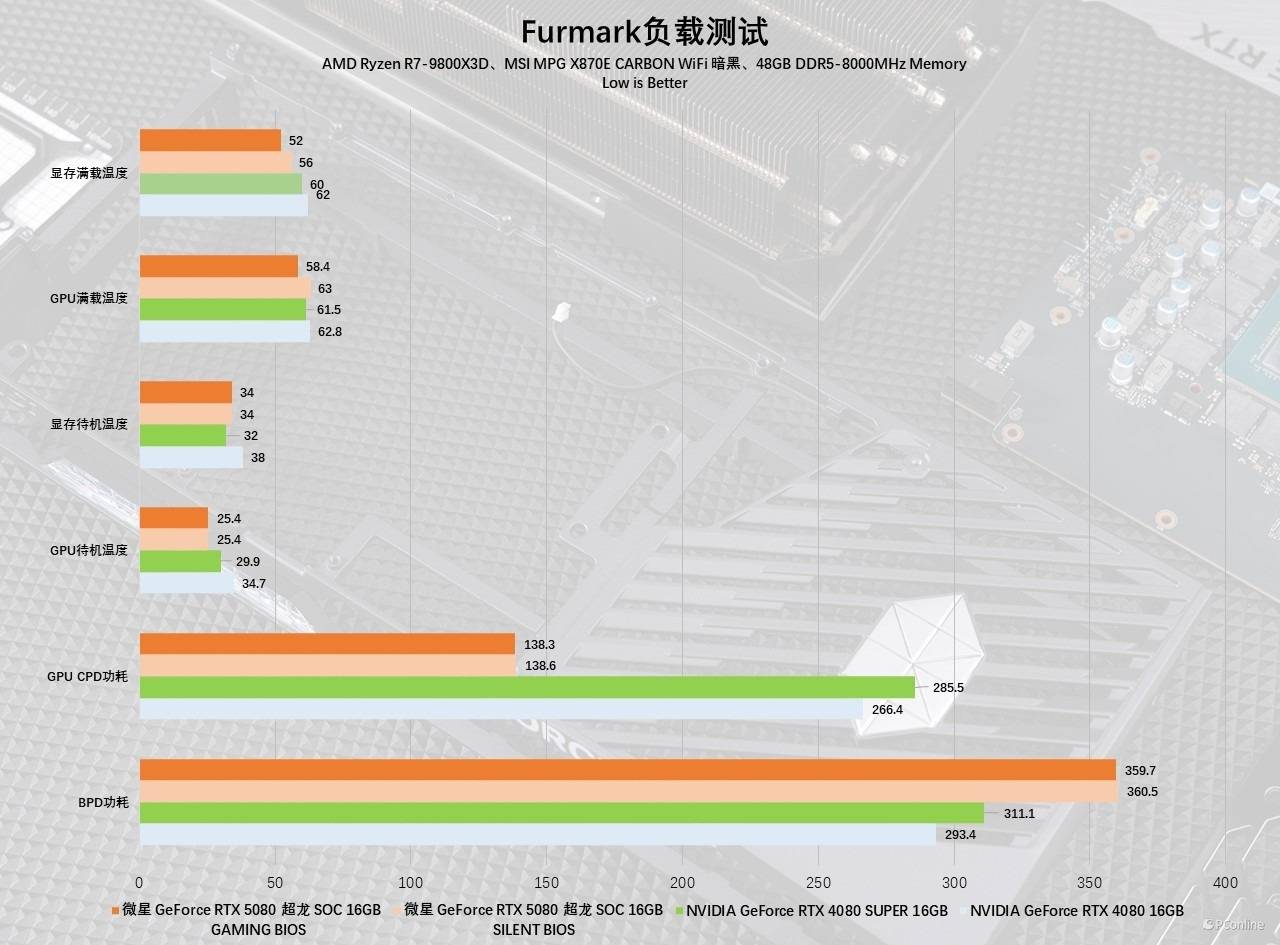
横向对比RTX 4080或RTX 4080 SUPER时可以看到,虽然新显卡的TDP提升了,不过整体的烤机功耗并不算高,特别是微星GeForce RTX 5080超龙SOC还配备双BIOS,无论是更激进的GAMING模式还是更安静的SILENT模式,核心与显存的温度都还控制得不错,属于是非常惊喜了。
评测总结
总的来说,微星GeForce RTX 5080超龙SOC的综合表现在一众RTX 5080中是绝对不输的,甚至可以说是Top1的存在。它不仅延续了微星超龙系列的一贯高端定位,更在多方面实现了自我超越,成为游戏玩家、AI开发者和内容创作者的共同焦点。

在外观设计方面,这款显卡就已经让人眼前一亮。以钻石切割的金属几何结构为灵感进行设计,不仅在视觉上极具冲击力,更在散热和结构强度上实现了突破。拉丝与磨砂工艺的巧妙运用,让显卡在不同光线下展现出细腻的层次感,这种设计语言不仅提升了产品的辨识度,更传递出一种高端产品的质感。
散热方面更是微星GeForce RTX 5080超龙SOC的一大亮点,其散热系统采用了全新设计的方形核心热管与独有的V形切口鳍片设计,配合高效的暴风7散热风扇以及真空腔均热板散热技术,确保了在满载环境下GPU温度依旧能够稳定在60℃以下。这个成绩说夸张一点都不为过,甚至不输一些水冷卡。同时显卡的噪音控制也非常出色,这种“游刃有余”的表现,正是高端显卡应有的素质。

性能方面自不必多说,RTX 5080作为RTX 50系的次旗舰,性能毋庸置疑的强,而作为超频版的微星GeForce RTX 5080超龙SOC更是将这种性能推向了新的高度。相比上一代的RTX 4080,它在多个维度上实现了显著提升,尤其是在游戏性能和AI计算能力方面。其中游戏方面,DLSS4技术的加入让显卡在高分辨率下的帧率表现更加出色,甚至在部分游戏中能够与上一代旗舰RTX 4090 D一较高下。
AI领域与创作领域对于这款显卡也是轻轻松松,不单止性能的提升带来了更优的创作体验,微星GeForce RTX 5080超龙SOC上16GB的大显存更是一个巨大的优势。在深度学习和复杂图形渲染等场景中,大显存能够显著提升处理效率,减少数据传输的时间成本。这种全方位的提升,使得微星RTX 5080超龙SOC能够满足不同用户群体的多样化需求。

最后再聊聊选购建议,考虑到目前RTX 5090一卡难求,甚至价格炒至2W以上的现状。对于绝大多数高端玩家和创作者来说,微星GeForce RTX 5080超龙SOC已能堪大用,如果你的预算在万元左右,考虑到这个卡是除RTX 5090/5090D外的顶级选择,那不妨关注一下。
免责声明:本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其内容真实性、完整性不作任何保证或承诺。由用户投稿,经过编辑审核收录,不代表头部财经观点和立场。
证券投资市场有风险,投资需谨慎!请勿添加文章的手机号码、公众号等信息,谨防上当受骗!如若本网有任何内容侵犯您的权益,请及时联系我们。
相关文章
-
小米汽车回应奥迪“喊话”:致敬quattro 祝冲刺挑战成功
2026-04-02259阅读
-
超10万笔低价单拒发货!盒马商家:运营失误 货损高达400多万
2026-04-02259阅读
-
SpaceX已秘密提交IPO,融资规模史上最大
2026-04-02259阅读
-
OpenClaw中国镜像上线!字节赞助,腾讯尴尬了!
2026-04-02259阅读
-
Anthropic试图挽救泄露源代码,却“误删”数千GitHub仓库
2026-04-02259阅读
-
黄仁勋谈20亿美元投资Marvell:AI推理转折点已至
2026-04-02259阅读
-
苹果50岁这天库克谈iPhone与未来:下个爆款在“软硬服交汇点”
2026-04-02259阅读
-
估值或超1.75万亿美元 SpaceX据报已秘密提交IPO文件
2026-04-02259阅读
-
和解失败 马斯克、美证监会将就推特欺诈案对簿公堂
2026-04-02259阅读
-
苹果都50岁了 大家怎么还在怀念它年轻的时候?
2026-04-02259阅读

