在人工智能界掀起波澜的DeepSeek团队,于近日震撼发布了其最新力作——DeepSeek-R1模型。这款开源模型一经问世,便在Github平台上迅速积累了超过4000颗星的瞩目成绩,成为大模型领域的一颗璀璨新星。
DeepSeek-R1的问世,不仅有力回击了此前关于其借鉴OpenAI o1的质疑,团队更是直接宣称:“我们的R1能与开源版的o1平分秋色。”这一自信宣言,无疑为业界带来了新的震撼。
尤为DeepSeek-R1在训练方式上实现了重大突破,摒弃了传统的SFT数据依赖,完全通过强化学习(RL)进行训练。这一创新之举,标志着R1已经具备了自我思考的能力,更加贴近人类的思维逻辑。

R1的卓越表现,让众多网友将其誉为“开源LLM界的AlphaGo”。在数学、代码、自然语言推理等多个领域,R1均展现出了与o1正式版不相上下的实力,甚至在某些基准测试中更胜一筹。
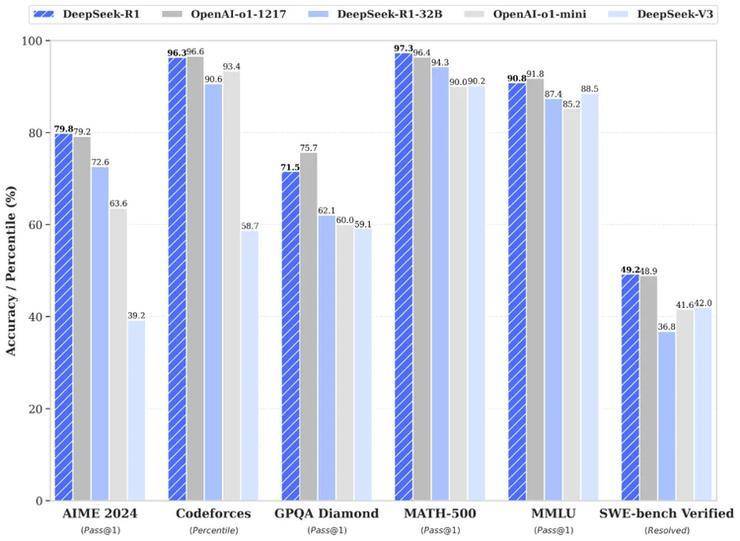
例如,在AIME 2024数学竞赛中,DeepSeek-R1取得了79.8%的优异成绩,略高于OpenAI的o1-1217。在MATH-500测试中,R1更是以97.3%的高分与o1-1217并驾齐驱,同时远超其他模型。在编程竞赛方面,R1同样表现出色,其在Codeforces上的Elo评级达到了2029,超越了96.3%的人类参赛者。
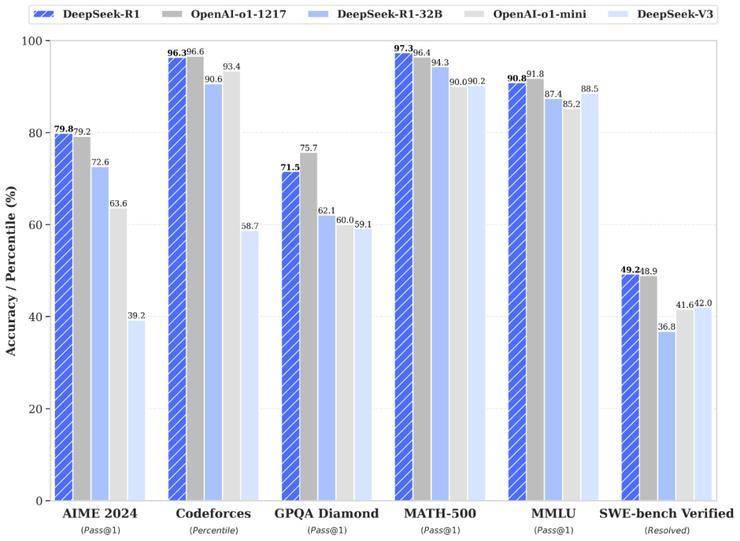
DeepSeek团队还将R1蒸馏出了6个小模型并开源给社区,参数从1.5B到70B不等。其中,蒸馏过的R1 32B和70B模型在性能上不仅超越了GPT-4o、Claude 3.5 Sonnet和QwQ-32B,甚至与o1-mini的效果相当。更令人惊叹的是,R1在实现这些卓越性能的同时,成本仅为o1的五十分之一。
除了R1在基准测试中的优异表现外,其发布即开源的训练数据集和优化工具也赢得了众多网友的赞誉。他们纷纷表示,这才是真正的Open AI精神。
DeepSeek-R1的成功背后,离不开其三大核心技术的支撑:Self play、Grpo以及Cold start。DeepSeek团队此次开源的R1模型共有两个版本,分别是DeepSeek-R1-Zero和DeepSeek-R1,两者均拥有660B的参数,但功能各有特色。
DeepSeek-R1-Zero完全摒弃了SFT数据,仅通过强化学习进行训练,实现了大模型训练中首次跳过监督微调的壮举。而DeepSeek-R1则在训练过程中引入了少量的冷启动数据,并通过多阶段强化学习优化模型,极大提升了模型的推理能力。
DeepSeek-R1在训练过程中还出现了“顿悟时刻”,模型自发地学会了“回头检查步骤”的能力。这一能力的涌现,并非程序员直接教授,而是在算法通过奖励正确答案的机制下自然形成的。这一发现,无疑为人工智能的发展带来了新的启示。
免责声明:本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其内容真实性、完整性不作任何保证或承诺。由用户投稿,经过编辑审核收录,不代表头部财经观点和立场。
证券投资市场有风险,投资需谨慎!请勿添加文章的手机号码、公众号等信息,谨防上当受骗!如若本网有任何内容侵犯您的权益,请及时联系我们。
相关文章
-
宝马携超30款车型亮相上海车展 新世代驾趣概念车全球首发
2025-03-315阅读
-
太极集团业绩崩盘,新董事长俞敏上任不足半年
2025-03-315阅读
-
新董事长杨秀明年度业绩首秀,重庆银行“增量不增质”?
2025-03-315阅读
-
新奥能源拟私有化,现有股东如何获利?
2025-03-315阅读
-
联想集团2025/26财年誓师大会顺利举行
2025-03-315阅读
-
谷歌计划将Gemini引入Chrome浏览器侧边栏
2025-03-315阅读
-
科技巨头与航天企业因卫星频谱资源展开法律争夺战
2025-03-315阅读
-
日料品类发展报告2025:品类持续回暖,细分赛道显现新潜力
2025-03-315阅读
-
KTC 5K 双模果粉屏显示器 H27P3 发布,3599 元
2025-03-315阅读
-
高通小至尊版芯片!REDMI首发骁龙8s Gen4
2025-03-315阅读

