最新一期权威大模型榜单:豆包1.5、商汤日日新V6并列国内第一
5月28日,权威大模型测评机构SuperCLUE《中文大模型基准测评2025年5月报告》全新出炉!
豆包1.5·深度思考模型(Doubao-1.5-thinking-pro)和商汤日日新 V6多模态模型(SenseNova-V6 Reasoner)共同摘得金牌,超越Gemini 2.5 Flash Preview,在国内大模型第一梯队领跑。
位居第二梯队的大模型包括DeepSeek-R1、NebulaCoder-V6、Hunyuan-T1以及DeepSeek-V3。
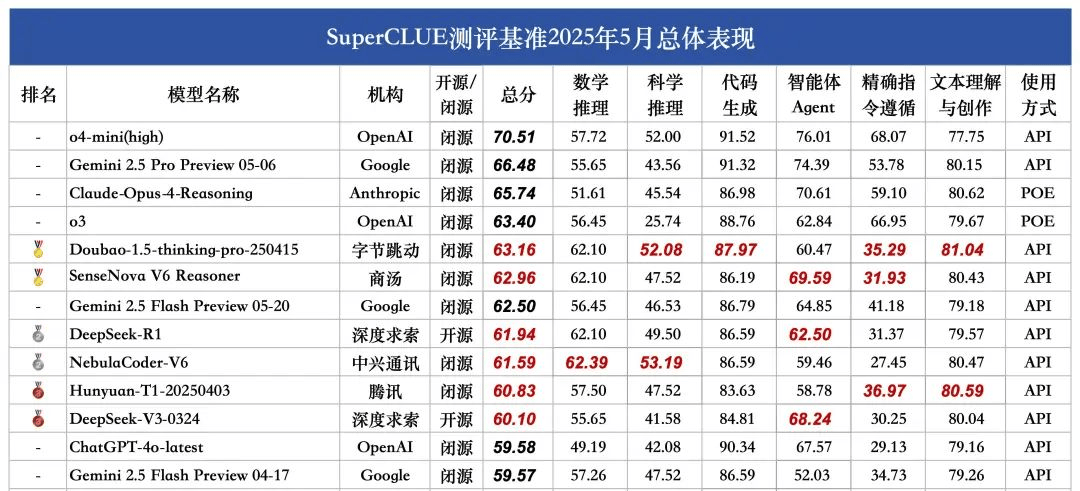
来自SuperCLUE
报告指出,国内外第一梯队大模型在中文领域的通用能力差距正在缩小。在国产大模型中,Doubao-1.5-thinking-pro-205415、SenseNova V6 Reasoner表现最为亮眼。国内推理模型竞争格局初露端倪。
SuperCLUE是行业权威的通用大模型的综合性测评基准。本次2025年5月报告聚焦通用能力测评,涵盖数学推理、科学推理、代码生成、智能体Agent、精确指令遵循、文本理解与创作六大任务,总量为1579道多轮简答题。
免责声明:本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其内容真实性、完整性不作任何保证或承诺。由用户投稿,经过编辑审核收录,不代表头部财经观点和立场。
证券投资市场有风险,投资需谨慎!请勿添加文章的手机号码、公众号等信息,谨防上当受骗!如若本网有任何内容侵犯您的权益,请及时联系我们。
相关文章
-
外国剁手党们,催着中国电商集体出海
2025-05-311阅读
-
雷军:小米汽车全国销售门店达298家 6月新增37家
2025-05-311阅读
-
我国造船产业前 4 月新接订单量保持全球第一
2025-05-311阅读
-
Opera 介绍 Neon AI 浏览器,内嵌 Operator 模型实现自动化操作
2025-05-311阅读
-
活该被罚40万!胖东来红内裤大结局,网红被判造谣赔到哭
2025-05-311阅读
-
随手播冲刺港股:年营收9895万 利润3814万
2025-05-311阅读
-
A18、8GB...苹果iPhone 17新料你敢信
2025-05-311阅读
-
再也不怕刷屏,微信界面空前清爽
2025-05-311阅读
-
安全公司曝光黑客山寨杀毒软件 Bitdefender 官网,实为提供木马
2025-05-311阅读
-
2025年中国园区网络行业发展现状、竞争格局及趋势预测
2025-05-311阅读

