近日,有研究团队提出一种新的强化学习方法,用于提升大语言模型的推理能力。该方法名为“交错推理”,由苹果公司与杜克大学联合开发,已在相关领域引发关注。
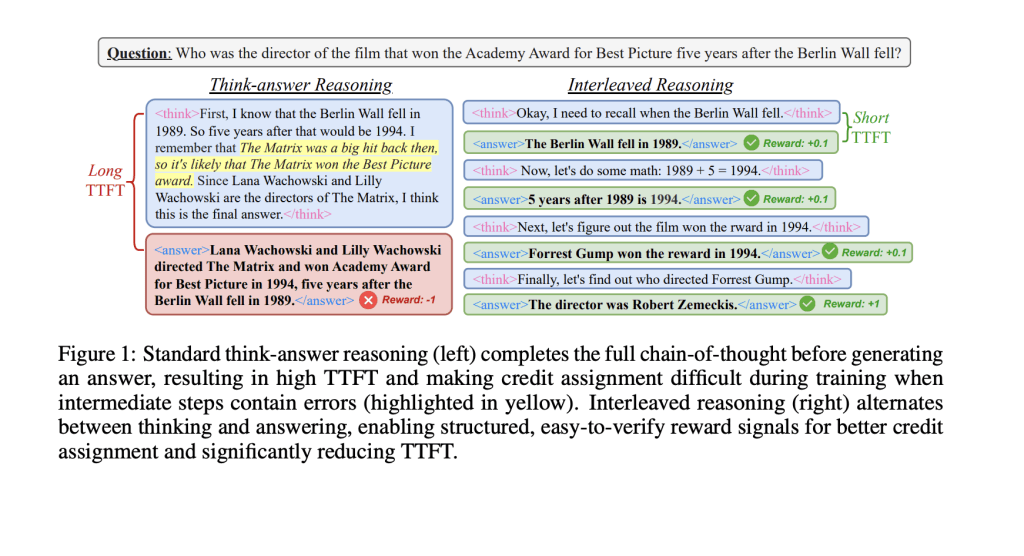
当前,主流的大语言模型在面对需要多步骤处理的复杂问题时,普遍采用“先思考后回答”的长链条推理模式。这种模式虽具逻辑性,但在实际应用中存在两个明显短板:一是输出响应较慢,难以满足对时效性要求较高的交互场景;二是由于推理过程较长,前期步骤若出现偏差,极易影响最终答案的准确性。
研究人员指出,与人类在交流过程中会逐步表达部分想法的方式不同,现有模型通常会在完成整个推理流程之后才输出最终结果,这种方式在效率和互动性上存在一定局限。
针对这一问题,“交错推理”提出了一种新思路:在模型推理的过程中,交替执行内部思维与输出中间答案(sub-answer)操作,从而优化整体响应速度与实用性。该方法基于强化学习框架设计,采用了特定训练模板,其中包含 `` 和 `` 标签,以指示模型在达到某些关键推理节点时输出阶段性结果。
为确保模型不仅关注局部输出,还能保持整体推理的准确性,研究团队构建了一套基于规则的奖励机制,涵盖格式合规性、最终准确率以及条件性中间准确率等指标。
实验结果显示,该方法在 Qwen2.5 模型(1.5B 和 7B 参数版本)上表现优异,响应速度提升了超过 80%,推理准确率也提高了近 19.3%。更值得关注的是,尽管模型仅在问答类和逻辑类数据集上接受过训练,但其在 MATH、GPQA 和 MMLU 等更具挑战性的任务中同样表现出较强的泛化能力。
研究还测试了多种奖励机制,包括全或无奖励、部分积分奖励及时间折扣奖励,其中以条件性奖励和时间折扣奖励的成效最为显著,远超传统训练方式的效果。
这项研究为提升大语言模型在复杂推理任务中的表现提供了一条新的技术路径,也为未来模型设计与优化带来了启发。
免责声明:本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其内容真实性、完整性不作任何保证或承诺。由用户投稿,经过编辑审核收录,不代表头部财经观点和立场。
证券投资市场有风险,投资需谨慎!请勿添加文章的手机号码、公众号等信息,谨防上当受骗!如若本网有任何内容侵犯您的权益,请及时联系我们。
相关文章
-
消息称 HMD 将推出 Rubber 1/1S 智能手表,支持血氧心率检测
2025-06-010阅读
-
vivo X Fold5 折叠屏手机通过 3C 认证,支持 90W 快充
2025-06-010阅读
-
深陷经营困局,多家白酒经销商疾呼重构利益分配格局!
2025-06-010阅读
-
城关区多轮驱动激发假日消费活力
2025-06-010阅读
-
雷军扬眉吐气:使用自研3nm芯片的15S Pro,好评率居然100%
2025-06-010阅读
-
今年消费品以旧换新销售额突破1万亿元
2025-06-010阅读
-
开心一刻:我开口就是一句:把你们店最贵的先拿一边去!
2025-06-010阅读
-
外国剁手党们,催着中国电商集体出海
2025-06-010阅读
-
小米SU7抢了谁的市场?不是特斯拉Model3、智界S7,是极氪01
2025-06-010阅读
-
领克:5月销量27630台,同比增长约26.9%
2025-06-010阅读

