6 月 3 日消息,字节跳动 Seed 团队上周宣布开源统一多模态理解和生成模型 BAGEL,该模型支持文本、图像和视频的统一理解和生成。
BAGEL 具有 70 亿个激活参数(总共 140 亿个),并在大规模交错多模态数据上进行训练。BAGEL 在标准多模态理解排行榜上超越了当前顶级的开源 VLMs,如 Qwen2.5-VL 和 InternVL-2.5,并且提供了与专业生成器如 SD3 竞争的文本到图像质量。
此外,BAGEL 在经典的图像编辑场景中展示了比领先的开源模型更好的定性结果。更重要的是,它扩展到了自由形式的视觉操作、多视图合成和世界导航,这些能力构成了超出以往图像编辑模型范围的“世界建模”任务。

具体来看,BAGEL 基于大语言模型进行训练,具备基础的推理和对话能力,能够处理图像和文本的混合输入,并以混合格式输出。
▲ 混合输入-混合输出
BAGEL 可生成较高质量、逼真的图像、视频或图文交错的内容。此外,还引入了长思维链 COT(Chain-of-Thought)模式,模型在生成之前可先“思考”。

▲ BAGEL 通过“思考”生成了一个穿着毛衣的鳄鱼玩偶
基于交错的多模态数据预训练,BAGEL 自然地学会了保留视觉特征和细微细节,并且能从视频中捕捉复杂的视觉运动,这些能力使得 BAGEL 在图像编辑上更为高效。


▲ 基于同一人物形象进行图像编辑
基于对视觉内容和风格的理解,BAGEL 仅使用较少的对齐数据,即可实现图片的风格切换,甚至还可转换至不同场景中。
▲ BAGEL 实现多种风格迁移
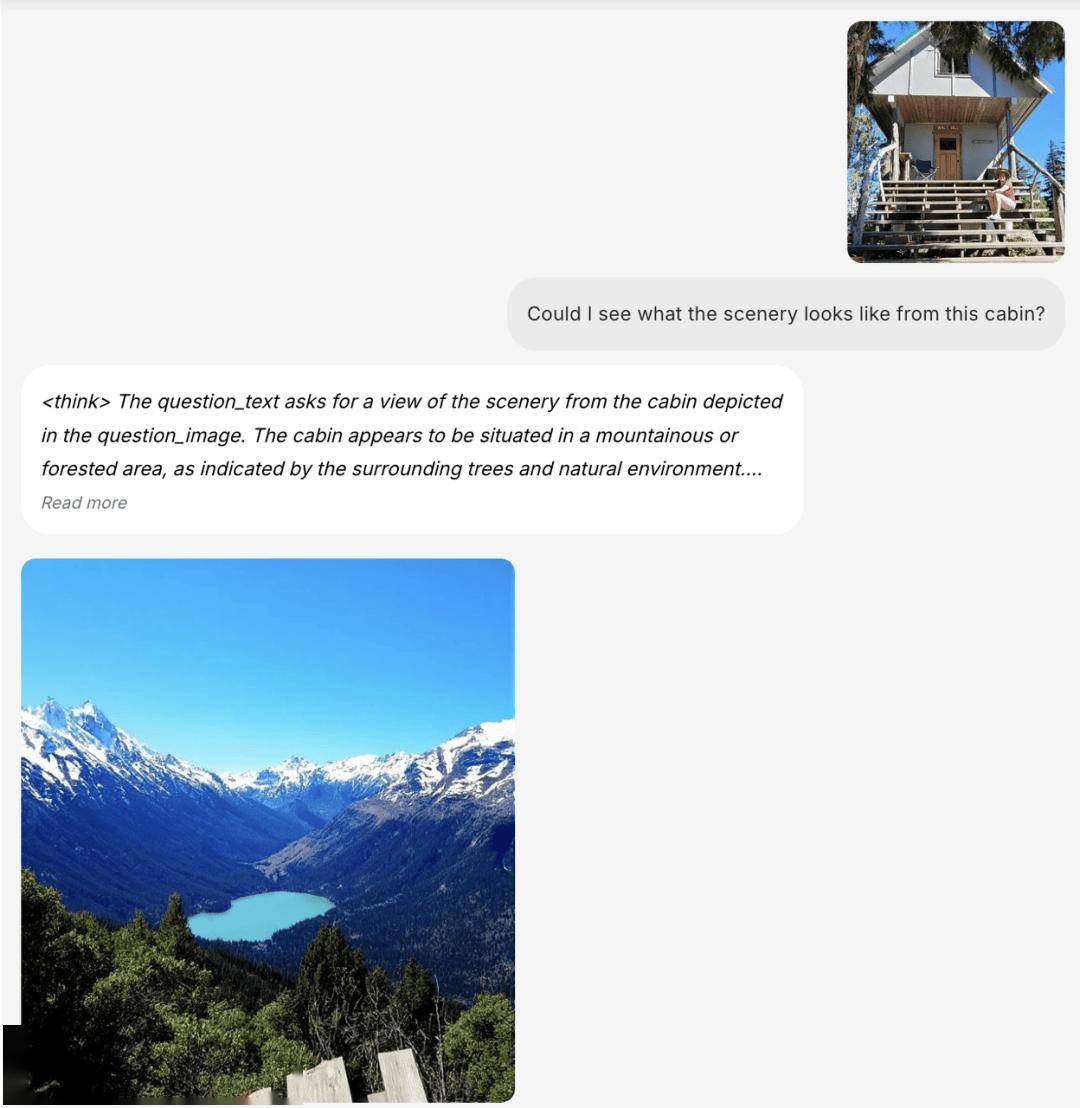
此外,BAGEL 还具备世界模型的基础能力,可实现世界导航、未来帧预测、3D 世界生成等更具挑战性的任务,并进行不同角度的旋转或视角切换。同时,BAGEL 还具备较强的泛化能力,不仅在各类真实场景中,还能在游戏、艺术作品、卡通动画等场景中实现导航。
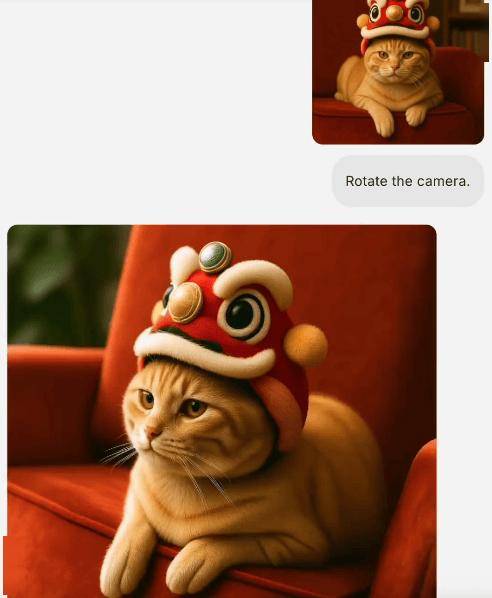
基于以上能力,BAGEL 还可通过一个统一的多模态接口,实现各项能力的复杂组合,进行多轮对话。
▲ 图片剪切-智能编辑-场景转换-风格转换组合功能
附 BAGEL 开源地址:
官网及体验入口:
GitHub 代码:
模型权重:
研究论文:
免责声明:本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其内容真实性、完整性不作任何保证或承诺。由用户投稿,经过编辑审核收录,不代表头部财经观点和立场。
证券投资市场有风险,投资需谨慎!请勿添加文章的手机号码、公众号等信息,谨防上当受骗!如若本网有任何内容侵犯您的权益,请及时联系我们。
相关文章
-
放弃内卷!内贸商家为何涌向东南亚?
2025-06-052阅读
-
淘宝验证火箭快递可行性,低空飞行125秒成功投送
2025-06-052阅读
-
OPPO与大众达成全球专利许可协议,彰显5G技术实力
2025-06-052阅读
-
UP主失误泄露马里奥赛车激活码引发热议
2025-06-052阅读
-
中思创新(北京)科技有限公司AI芯片技术探析
2025-06-052阅读
-
【月报】5月物流科技动态回顾:1688将下线“官方物流”标签
2025-06-052阅读
-
饶毅:75岁董事长秀肌肉代言的是“假药”!公司最新回应!
2025-06-052阅读
-
山东饲料龙头要养猪!邦基科技拟收购7家猪企股权,股价提前“抢跑”
2025-06-052阅读
-
优志愿鸿蒙版:AI助力高考志愿填报,智能高效更省心
2025-06-052阅读
-
AMD联合生态伙伴启动中国行业生态共建计划,共拓企业级市场新机遇
2025-06-052阅读

