随着生成式AI技术的爆发式增长,AI大模型开始渗透至手机领域,一线厂商已经把AI应用集成到各自最新的产品中,并且在以惊人的速度迭代。为了进一步提升大模型部署的效能,荣耀基于应用腾讯云TencentOS Server AI中提供的TACO-LLM加速模块部署DeepSeek-R1等开源大模型,并应用荣耀企业内部等场景,稳定性、可靠性、推理性能均大幅提升。
在推理平台场景中,荣耀侧重关注框架效能、稳定性、运行状态监控及应急预案等特性。使用TACO-LLM进行推理任务后,在DeepSeek-R1 满血版场景下,相对于荣耀原始线上业务性能,TTFT(首Token 延迟)P95 的响应时间最高降低6.25倍,吞吐提升2倍,端到端延迟降低100%。在社区最新版本sglang场景下,TTFT P95的响应时间最高降低12.5倍。
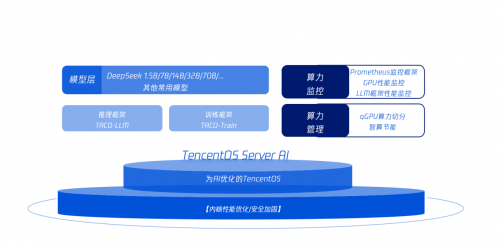
腾讯云TACO-LLM之所以能够对荣耀业务的性能提升如此明显,主要的得益于多种投机采样技术核心能力:大语言模型的自回归解码属性无法充分利用GPU的算力,计算效率不高,解码成本高昂。而TACO-LLM通过投机采样的方式,从根本上解决了计算密度的问题,让真正部署的大模型实现“并行”解码,从而大幅提高解码效率。
荣耀大数据平台部相关负责人表示:“荣耀使用腾讯云 TACO-LLM 打造高性能的AI底座,部署稳定可靠,提升了性能加速体验。”
TencentOS Server AI加速版中提供的TACO-LLM加速模块,针对企业级AI模型私有化部署挑战,对大语言模型业务进行了专门的内核运行优化,用于提高大语言模型的推理效能,提供兼顾高吞吐和低延时的优化方案,能够“无缝”整合到现有的大模型部署方案中。
免责声明:本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其内容真实性、完整性不作任何保证或承诺。由用户投稿,经过编辑审核收录,不代表头部财经观点和立场。
证券投资市场有风险,投资需谨慎!请勿添加文章的手机号码、公众号等信息,谨防上当受骗!如若本网有任何内容侵犯您的权益,请及时联系我们。
相关文章
-
买黄金也有消费补贴了!上海有门店金价“低至”705元/克,有人找跑腿跨城代购
2025-06-090阅读
-
智谱COO张帆将离职?官方回应:其创业项目已获智谱投资
2025-06-090阅读
-
经营抽检不合格食品 零售巨头沃尔玛被罚没28.9万元
2025-06-090阅读
-
首发国产一英寸!余承东晒华为Pura 80真机拍摄视频 强得飞起
2025-06-090阅读
-
首发国产一英寸!余承东晒华为Pura 80真机拍摄视频 强得飞起
2025-06-090阅读
-
1699元!小米智能门锁2指静脉增强版发布:自带猫眼+可视大屏
2025-06-090阅读
-
红魔电竞平板3 Pro支持通讯融合:平板可无缝接听手机电话
2025-06-090阅读
-
古尔曼称苹果 iOS 26 AI 电池管理或 9 月随 iPhone 17 Air 推出
2025-06-090阅读
-
感光能力大增!华为Pura 80视频能力重磅升级:大光比明暗细节完美还原
2025-06-090阅读
-
国内首个混合推理模型!阿里千问3开源首月全球下载量破千万
2025-06-090阅读

