6 月 11 日消息,科技媒体 marktechpost 昨日(6 月 10 日)发布博文,报道称 meta 公司推出 LlamaRL 框架,采用全异步分布式设计,在 405B 参数模型上,LlamaRL 将强化学习步骤时间从 635.8 秒缩短至 59.5 秒,速度提升 10.7 倍。
注:强化学习(Reinforcement Learning,RL)通过基于反馈调整输出,让模型更贴合用户需求。随着对模型精准性和规则适配性的要求不断提高,强化学习在训练后阶段的重要性日益凸显,持续优化模型性能,成为许多先进大语言模型系统的关键组成部分。
将强化学习应用于大语言模型,最大障碍在于资源需求。训练涉及海量计算和多组件协调,如策略模型、奖励评分器等。模型参数高达数百亿,内存使用、数据通信延迟和 GPU 闲置等问题困扰着工程师。
meta 推出的 LlamaRL 框架,采用 PyTorch 构建全异步分布式系统,简化协调并支持模块化定制。通过独立执行器并行处理生成、训练和奖励模型,LlamaRL 大幅减少等待时间,提升效率。
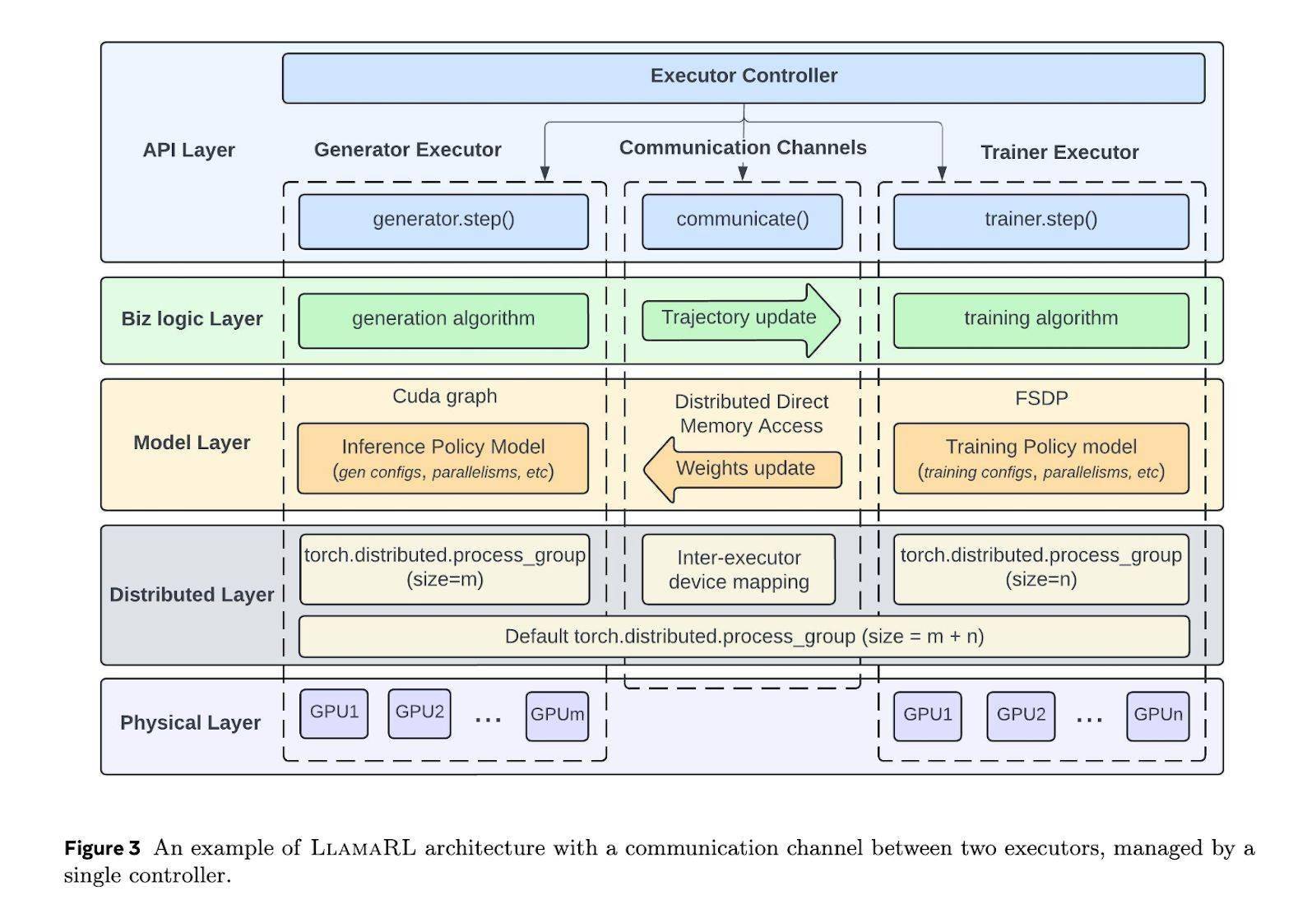
LlamaRL 通过分布式直接内存访问(DDMA)和 NVIDIA NVlink 技术,实现 405B 参数模型权重同步仅需 2 秒。
在实际测试中,LlamaRL 在 8B、70B 和 405B 模型上分别将训练时间缩短至 8.90 秒、20.67 秒和 59.5 秒,速度提升最高达 10.7 倍。

MATH 和 GSM8K 基准测试显示,其性能稳定甚至略有提升。LlamaRL 有效解决内存限制和 GPU 效率问题,为训练大语言模型开辟了可扩展路径。
免责声明:本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其内容真实性、完整性不作任何保证或承诺。由用户投稿,经过编辑审核收录,不代表头部财经观点和立场。
证券投资市场有风险,投资需谨慎!请勿添加文章的手机号码、公众号等信息,谨防上当受骗!如若本网有任何内容侵犯您的权益,请及时联系我们。
相关文章
-
宜昌40余场主题促消费活动火热来袭
2025-06-1316阅读
-
茶饮与平价冲击下的哈根达斯
2025-06-1316阅读
-
近五成超市企业去年亏损,为何它们却在逆势增长?
2025-06-1316阅读
-
中国时尚消费市场规模将达2-3万亿,这场盛典带你读懂国潮
2025-06-1316阅读
-
以“即买即退”为枢纽,岭南控股创新联动打造入境消费“岭南样板”
2025-06-1316阅读
-
陆瑶:民营经济与金融法治的共振时代丨清华经管说
2025-06-1316阅读
-
如何选择合适的CRM企业管理软件?
2025-06-1316阅读
-
荔湾时尚产业:从个体经营走向品牌运营
2025-06-1316阅读
-
“输出 Labubu”,跨境电商在品牌出海的前线
2025-06-1216阅读
-
当天就能来回!成都6个免费玩水地点推荐!
2025-06-1216阅读

