进入2025年的夏季后,AI圈也变得愈发躁动。就在不久前,OpenAI宣布将以64亿美元全资收购前苹果首席设计师乔尼・艾维的AI设备初创公司io后,meta方面也开始行动。近日有消息显示,meta已同意以148亿美元收购人工智能数据标注公司Scale AI的49%股份,这将是该公司有史以来最大规模的外部投资。

meta的这一举措,被美国AI圈解读为扎克伯格大刀阔斧重组该公司人工智能业务的一部分。据知情人士透露,扎克伯格近期正在组建被称为“超级智能组”(Superintelligence Group)的AI实验室,并将其视为meta的最高优先事项,以在日趋激烈的AI技术竞赛中保持市场竞争力。
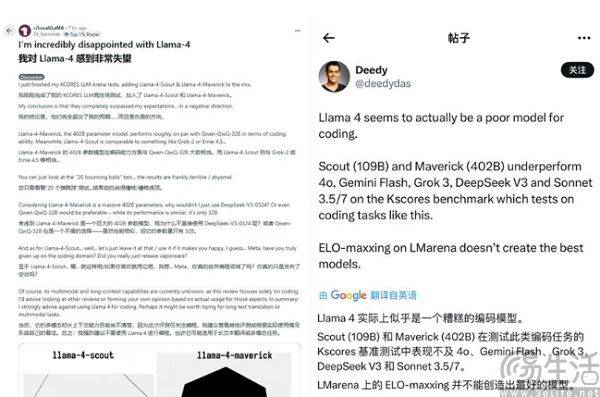
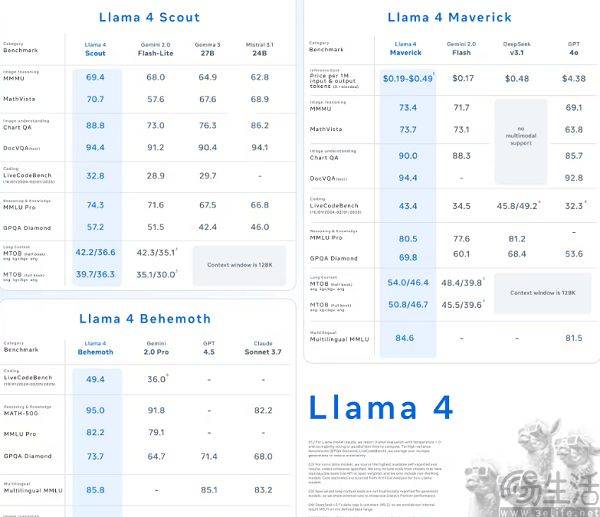
扎克伯格对meta AI“动刀”,或许源自于他们最新的Llama 4遭遇滑铁卢。作为meta在4月推出的最新模型,Llama 4在推出时曾号称"2万亿参数"、"指标精度超越GPT-4",结果在第三方基准测试中直接成了吊车尾,与官方公布的测评成绩形成强烈反差,在诸如代码、长文本等场景悉数翻车。
以至于在扎克伯格的视角下,LIama 4成了“王婆卖瓜,自卖自夸”的典型。其实大模型翻车并不奇怪,可为何LIama 4不及预期会引发meta如此剧烈的反应呢?因为不同于OpenAI、xAI、Anthropic、谷歌,meta的AI路线图截然不同。该公司的策略是押注开源模型,更关注与学界、而非业界的联系,试图通过开源赢得AI开发者和研究者的青睐,再通过这些人来将meta AI的影响力渗透到普通用户中。
不得不说,meta这番另辟蹊径的做法是有效果的,此前LIama模型就曾长期被业界视为是“救命稻草”,大量的AI研究、AI创业都是基于LIama而来。可是中国开源模型的崛起速度超过了硅谷的想象,深度求索的DeepSeek、阿里的Qwen都让meta的Llama不再是唯一可用的开源模型,这就意味着他们在AI赛道中开始掉队。
其实扎克伯格对于meta现有AI部门不满是有迹可循的,先是旗舰模型LIama 4 Behemoth延期,紧接着meta方面宣布AI部门重组,拆分为“AI产品”与“AGI基础”两大团队。所以meta如今选择收购Scale AI也并不让人感到意外,因为后者作为AI行业首屈一指的数据提供商,能弥补meta在数据上的短板。
meta在训练AI时遇到了数据荒,这并非天方夜谭。作为全球最大的社交平台,meta旗下的Facebook、Instagram、Threads拥有数以十亿计的用户,后者天然就是数据的贡献者。可问题在于,对于目前AI大模型预训练来说,社交平台产生的数据属于低质量数据,不可能直接拿来就用。
去年,谷歌的AI搜索功能AI Overviews(AI概览)曾输出“用胶水将芝士固定在披萨上”、“推荐摄入石头获取营养”等令人匪夷所思的错误,其实就是AI概览采信了Reddit用户发的帖子。可问题是Reddit用户的原帖并不是正经的科普,而是为了搞笑、“整活”。
当用户查询如何将芝士和披萨饼胚粘在一起时,AI给出“加点胶水”这样的回答并不是无厘头,而是因为在AI的视角下,胶水作为粘合剂确实能让芝士和披萨饼胚粘在一起。同时AI概览推荐用户吃石头补充营养,也是因为石头里真的有钙、镁、钠、钾等人体所需的微量元素。
为了防止这类“有毒”的低质量数据进入AI大模型的数据库,出现“垃圾进,垃圾出”的效果,就需要数据标注。为了有效利用海量的社交数据,所以meta选择收购Scale AI并非不能理解。
看到这里,或许有的朋友会问,为什么meta不自己干呢?其实这是因为他们不可能把宝贵的人力资源用于数据标注。
数据标注工作是将各种图片、文本、视频等数据集打上标签,使得其成为二进制、计算机可以理解和识别的信息,并将无法使用的数据清洗出去。数据标注的技术门槛其实相当之低,标出图片中的行人、车辆、建筑,在一段语音中判断说话人的语气就是这个工作的主要场景,基本完成了初级教育的人就能轻松胜任。
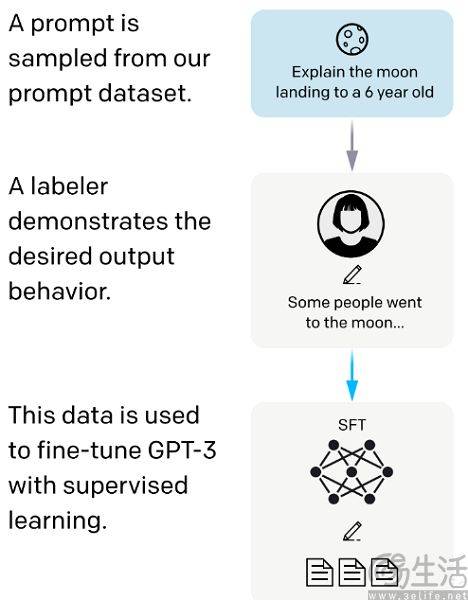
而数字标注从业者的工作内容,就是对着电脑屏幕,根据开发者给定的规则来为数据打上各式各样的标注,与流水线上工人干的活没什么区别,属于非常典型的“赛博搬砖”。比如Scale AI的核心竞争力,就是在肯尼亚、菲律宾的24万数据标注员。以至于有AI创业者调侃,Scale AI与AI的关系仅限于公司名称。
反观作为硅谷大厂的meta,据《华尔街日报》2024年的相关报道显示,他们在2023年支付给员工的工资中位数约为29.6万美元,是硅谷巨头中最多的。按照每周40小时的标准工时计算,Mete员工的平均时薪是144美元,所以meta用自家员工来做数据标注工作就属于暴殄天物。
相信有不少人认为meta花费148亿美元买下Scale AI,就好像当年用10亿美元收购Instagram一样,都是既加强自身竞争力,又能遏制竞争对手的妙手。然而许多在AI从业者看来,这一次扎克伯格或是病急乱投医。
如果是在DeepSeek-R1问世前,meta收购Scale AI还称得上是一桩不错的交易,meta也确实能借助Scale AI的廉价劳动力来丰富数据供给,从而训练更大规模的Llama模型。可DeepSeek-R1已经证明了⽆需监督微调的预训练步骤、直接通过强化学习(RL) 训练,也能让模型展现出卓越的推理能⼒。
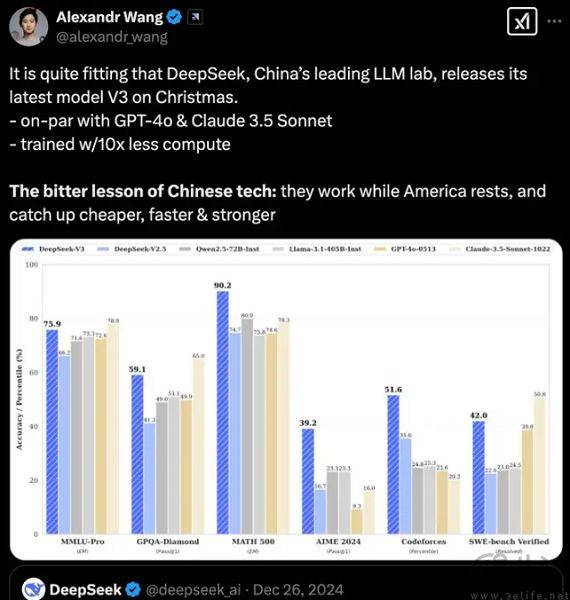
监督式微调则指的是利用标注数据来调整预训练大语言模型,使得其适应特定下游任务的过程。如果不需要监督式微调,数据标注也就失去了价值。这也是为什么今年年初DeepSeek-R1爆红时,Scale AI创始人Alexandr Wang会歇斯底里地攻击DeepSeek。
其实DeepSeek真正直接打击的还不是英伟达,而是Scale AI。当然,完全放弃监督式微调、纯粹依靠RL也过于极端,业界当下的主流是RL为主、监督式微调为辅,尽量寻找博士水平(PhD-Level)的专家标注出高质量数据。换而言之,除非DeepSeek的路线被证明不能抵达人工智能领域的“圣杯”AGI,否则meta这次花大价钱其实是买了一个注定会没落的AI独角兽。

当然,对于拥有720亿美元现金和短期等价物的meta而言,花148亿美元买一个能马上缓解AI掉队危机的Scale AI,也不是什么不可接受的事情。
免责声明:本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其内容真实性、完整性不作任何保证或承诺。由用户投稿,经过编辑审核收录,不代表头部财经观点和立场。
证券投资市场有风险,投资需谨慎!请勿添加文章的手机号码、公众号等信息,谨防上当受骗!如若本网有任何内容侵犯您的权益,请及时联系我们。
相关文章
-
爱康集团董事长张黎刚:20载匠心淬炼,打造全球康养新范式
2025-06-1414阅读
-
任正非称芯片问题没必要担心!黄仁勋回应:华为能满足中国需求 也能供应其他地区
2025-06-1414阅读
-
中非企业家对话谋篇、项目发布签约,麻业湘企:我们的专利技术在非洲找到了一片广阔发展的沃土
2025-06-1414阅读
-
雷军回应小米SU7 Ultra纽北破纪录
2025-06-1414阅读
-
指控偷特斯拉技术!马斯克起诉华人前员工
2025-06-1414阅读
-
任正非:我们芯片落后美国一代,但通过集群,能补上来
2025-06-1414阅读
-
卫龙董事长刘卫平:致力于传统美食的娱乐化、休闲化、便捷化、亲民化
2025-06-1414阅读
-
坐拥39座商场,娶小21岁女星的富豪沈国军,今身价超630亿
2025-06-1414阅读
-
任正非:企业的寒冬,不是靠熬过去的
2025-06-1414阅读
-
瑞欧威尔CEO李波:以头戴计算机产品重塑工业作业模式
2025-06-1414阅读

