云与 AI 成为基础设施与平台的当下,运维团队正面临多重挑战:指标、日志、跟踪数据割裂形成的 “数据孤岛”,被动响应机制导致的平均修复时间攀升,传统监控在动态微服务架构中的失效等等。
而在现代应用开发的背景下,可观测性可以从各种来源收集和分析数据:日志、指标和追踪 —— 以深入了解在你环境中运行的应用程序的行为。而通过可观测性方案 + AI,也能为现代 IT 系统实现更加智能的可观测性。
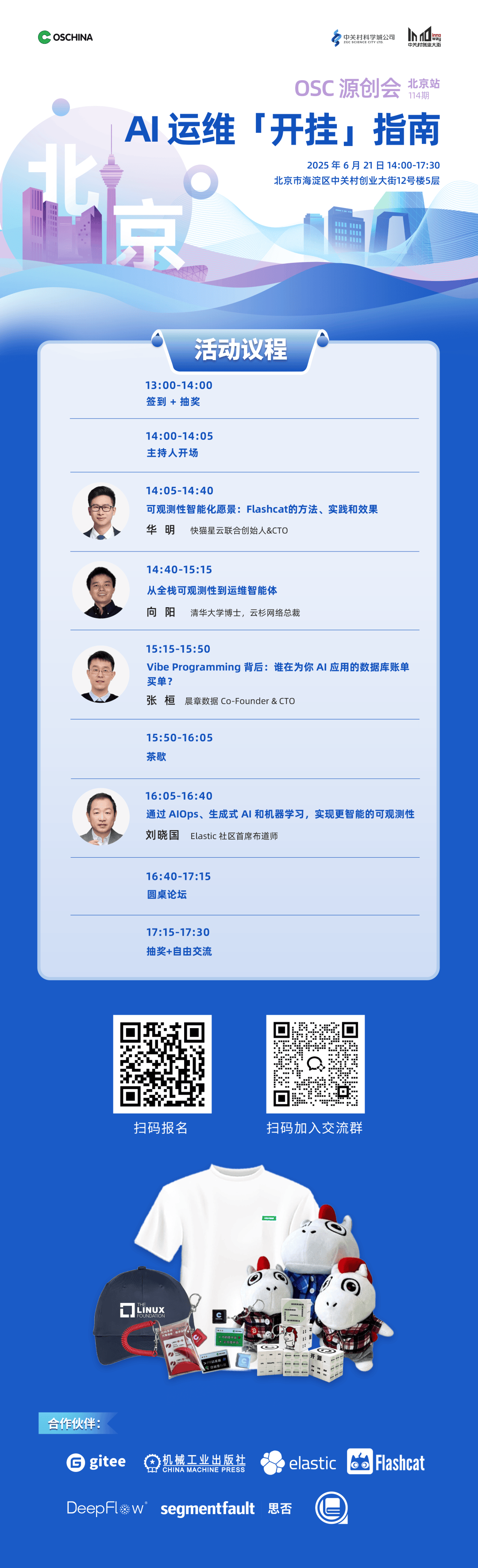
本周六,第 114 期 OSC 源创会将在北京举办,以 “AI 运维「开挂」指南”为主题。Elastic 社区首席布道师刘晓国将出席活动,并发表 《通过 AIOps、生成式 AI 和机器学习,实现更智能的可观测性》主题演讲。
在活动正式开始前,先来简单了解下可观测方案。
OSCHINA:您提到现代系统需从 “被动响应转向主动防御”,当前企业在可观测性实践中面临的最大痛点是什么?传统监控方案为何难以应对云原生环境下的复杂性?
刘晓国:
数据量大,存储成本高、海量数据处理压力大,很多企业的可观测性数据(指标,日志及跟踪)存在于不同的数据库中,从而造成数据孤岛,手动关连它们或通过一些工具进行转化比较困难。当真正的事件发生后,很难找到真正的原因。
另外人工分析这些数据几乎是不可能的,特别是想从被动响应转向主动防御。 Elastic 的全面可观测性方案可以采用机器学习的方法来对实时数据进行分析,并查看异常事件,从而完成从被动响应转向主动防御的需求。这些异常的事件可以结合通知 / 告警的方式以不同的形式发送给运维人员。
云原生环境中的服务频繁启动,停止和扩展,传统的监控很难实时地跟踪这些变化。另外,传统监控难以在云环境中捕获服务的调用链和依赖关系。Elastic 的服务图可以很方便地显示各个服务之间的调用关系,并在图上以不同的颜色显示该服务的健康状态。我们可以结合机器学习及大模型来进一步解释及提供修正的方案。
OSCHINA:Elastic 可观测性方案的优势是什么?
刘晓国:
Elastic 可观测性方案把指标,日志,跟踪及通用分析数据保存于同一个数据库中,尽管存在于同一个平台的不同索引里。Elastic 使用 ECS (Elastic Common Schema) 语义语法来定义统一的字段名称。这样不同的索引还是可以通过一些字段进行关联。
当一个事件发生时(比如响应缓慢可以在跟踪视图可见),我们可以同时同时在一个平台查看日志,指标,从而找出真正的事件原因。Elastic 全观测性方案可以更快地位 IT 团队找出根因,而不用在各个不同的平台里进行手动关联,或通过一种转换的方式来进行操作。
OSCHINA:在您遇到的案例中,是否有某个问题通过传统监控完全无法捕捉,却因 Universal Profiling 的‘全栈可见性’意外暴露?当时团队如何反应?
刘晓国:
Elastic Universal Profiling™ 是一种全系统、始终在线、连续的分析解决方案,无需代码检测、重新编译、主机上调试符号或服务重新启动。
通用分析利用 eBPF在 Linux 内核空间内运行,以不引人注目的方式以最小的开销仅捕获所需的数据。它可以帮我们定位消耗时间最多的函数以及这些函数的调用情况,并以火焰图的形式表达出来。它可以帮我们了解整个基础架构中哪些代码行始终消耗 CPU 资・源。我们可以通过 Universal Profiling 工具来优化我们的代码设计。
OSCHINA:AIAssistant 生成的操作建议需要人工复核吗?在您经历的案例中,运维团队对 AI 建议的信任度如何建立?
刘晓国:
我们的 AI Assistant 是基于 LLM RAG 基础之上的智能助手。我们可以建立自己的知识库,从而消除人工智能在推理时产生的幻觉。这些知识库存在于 Elastic 自己的索引里,是可以由运维人员自己创建的,或者直接有运营手册直接导入的。这些知识库可以来自 github,runbook, playbook 等。
另外 Elasticsearch 的文档非常全面,很多大模型对 Elasticsearch 的文档进行了充分的训练。通常来说,产生幻觉的机会还是蛮少的。我们将来甚至可以推出自己的大模型。针对有些敏感的操作,我们可以在助手里做出相应的选择。
在 AI 进行回答问题之前,通常会查看自己的知识库得到最相近的答案。如果 AI 提供的推理是建立在自己的知识库之上,或者我们在自己平时积累的解决方案之上,那么 AI 推理提出的解决方案还是相当可以接受的。
OSCHINA:您认为 LLM+Observability 的结合会催生哪些新范式?未来是否可能出现 “自主修复系统”?
刘晓国:
是的,这种完全可能。目前在 Elastic 的可观测性方案中,我们使用 AIOps 来针对可观测性提供解决方案。由于 LLM 具有良好的推理及总结功能,甚至它还可以帮我们关联不同索引里的数据。结合私有知识库,LLM+Observability 为我们的可观测性提供良好的解决方案。Elastic 的可观测性其实还有一个叫做 AutoOps 的解决方案。其实主要是针对集群的运行及查询,摄入的监控,并提出相应的解决方案。
OSCHINA:对于资源有限的中小团队,部署智能可观测性最应规避的‘过度设计’陷阱是什么?能否分享一个最小可行方案的搭建路径?”
刘晓国:
我觉得尽量采用通用标准,比如 OpenTelemetry 从而规避锁定厂商。另外,尽量避免工具泛滥,膨胀。工具多了,维护的成本也会增加,带来的问题也会很多。如把需要的数据采集到一个数据库中,而不是分散到不同的平台中。还有最好采用一下比较成熟的解决方案,而不是一些未经得到证实的方案。
Elastic 其实已经提供了一个比较简介的部署方案,从数据摄取,处理,展示,搜索,及到事件的捕获,通知 / 告警。在同一个平台即可搞定所有的事。我们还可以结合人工智能来帮助我们摄取,优化,推理,并提供解决方案。
OSCHINA:开发者需掌握哪些新技能来驾驭智能运维时代?
刘晓国:
日志,指标及跟踪的数据采集,处理及分析技能(Elastic Stack, OpenTelemetry 等)
数据整合的能力,比如数据采集,清洗,丰富等
熟悉 Kafka, Spark, Flink, Logstash, Beats, Elastic Agents 等数据处理框架。
AI/ML 能力。Elastic 中使用 ML 来监测异常事件。虽然开发者不需要掌握很深的 ML 能力,但是知道其作用并如何使用即可。。如果使用 LLMs 来帮助我们分析文件,解决问题。在海量的数据里找到洞察。
具有使用一些构建易用,直观的运维可视化界面能力(比如 Kibana, Grafana 等)
通知及告警
AI agents
OSCHINA:Elastic 近年从搜索引擎扩展到可观测性、安全甚至生成式 AI领域,这种跨界拓展背后的核心逻辑是什么?在您看来,未来 3 年 Elastic 最可能颠覆的 “下一个生态位” 会是什么?
刘晓国:
其实 Elastic 在很多年前已经进入到可观测性及安全领域。早期我们还有企业搜索。这些构成了 Elastic 的三大技术方案。目前企业搜索已经退出,更多地集成到我们的 Search 解决方案里。Elastic 在过去的三年里大量投入到 AI 领域。我们的向量搜索库 Elasticsearch 是世界上下载最多的数据库。
在未来,我们将围绕 AI 打造智能解决方案。LLMs 为这些提供了良好的基础。我们结合 MCP 这种 AI agents 通过自然语言的方式对我们的数据进行查询,分析,并提出解决方案。AI 智能体在未来肯定会越来越聪明,并为我们的可观测性带来自动处理的能力!
免责声明:本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其内容真实性、完整性不作任何保证或承诺。由用户投稿,经过编辑审核收录,不代表头部财经观点和立场。
证券投资市场有风险,投资需谨慎!请勿添加文章的手机号码、公众号等信息,谨防上当受骗!如若本网有任何内容侵犯您的权益,请及时联系我们。
相关文章
-
OpenAI CEO首次官宣:GPT-5将于今夏面世 AI能力重大飞跃
2025-06-194阅读
-
梦舟飞船成功进行零高度逃逸试验
2025-06-194阅读
-
广西工业版人形机器人下线
2025-06-194阅读
-
我国共13人上过太空,为何只有2位是航天英雄,其他是英雄航天员
2025-06-194阅读
-
蚂蚁国际 Alipay+ 发布首个面向智能眼镜的嵌入式全球支付方案
2025-06-194阅读
-
银河系有10万个地球,全宇宙又有多少个地球?
2025-06-194阅读
-
清华惊现神秘高科技组织?团队独家回应→
2025-06-194阅读
-
下马威?美论坛:如果中国禁止美加入中国空间站,美有权将其击落
2025-06-194阅读
-
数亿光年范围,内部却没有星系,宇宙空洞有多可怕?
2025-06-194阅读
-
火星逆行影响下的2025:哪些星座事业进展顺利?
2025-06-194阅读

