谷歌DeepMind机器人AI模型实现本地化运行:可完成系鞋带等高难度任务
6月24日消息,谷歌DeepMind今日发布博客文章,宣布推出一种全新的 Gemini Robotics On-Device本地化机器人AI模型。

该模型基于视觉-语言-动作(VLA)架构,无需云端支持即可实现实体机器人控制。核心特性包括:
技术能力:
独立运行于机器人设备,支持低延迟响应(IT之家注:适用于网络不稳定场景,如医疗环境)
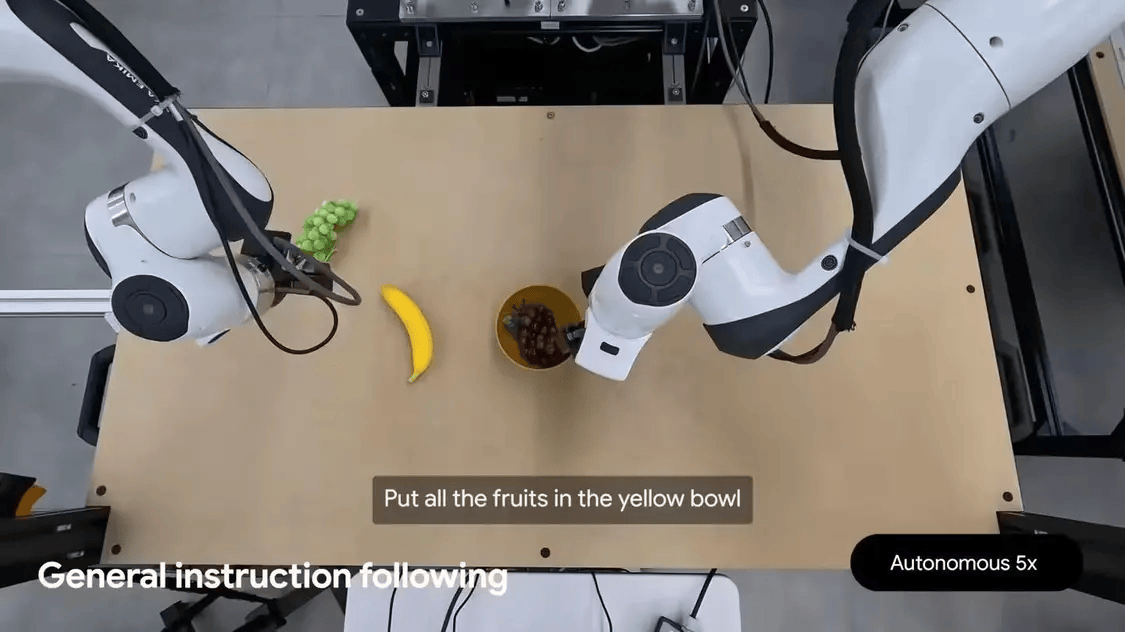
完成高精度操作任务(如打开包袋拉链、叠衣服、系鞋带)
双机械臂设计,适配ALOHA、Franka FR3及Apollo人形机器人


开发适配:
提供Gemini Robotics SDK工具包
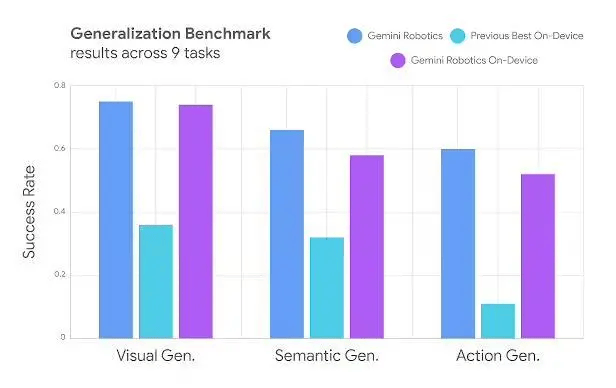
开发者通过50-100次任务演示即可定制新功能
支持MuJoCo物理模拟器测试
安全保障:
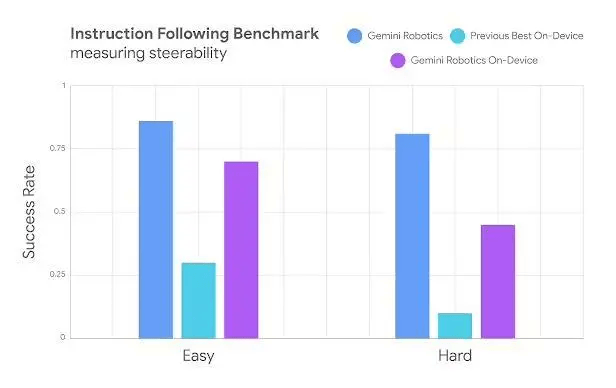
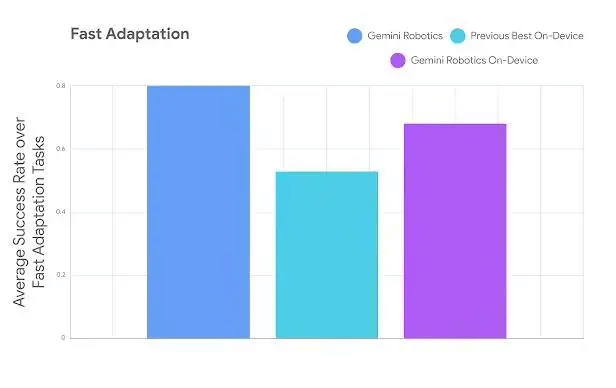
通过Live API实施语义安全检测
底层安全控制器管理动作力度与速度
开放语义安全基准测试框架
项目负责人Carolina Parada表示:“该系统借鉴Gemini多模态世界理解能力,如同 Gemini生成文本/代码/图像那样生成机器人动作”。
谷歌表示,该模型现在只面向可信测试计划开发者开放,基于Gemini 2.0架构开发(落后于Gemini 2.5最新版本)。
免责声明:本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其内容真实性、完整性不作任何保证或承诺。由用户投稿,经过编辑审核收录,不代表头部财经观点和立场。
证券投资市场有风险,投资需谨慎!请勿添加文章的手机号码、公众号等信息,谨防上当受骗!如若本网有任何内容侵犯您的权益,请及时联系我们。
相关文章
-
全球首台Rokid Glasses在蓝思科技湘潭基地下线
2025-06-2511阅读
-
报名启动!7月4日举办AIGC与元宇宙融合发展论坛|2025全球数字经济大会
2025-06-2511阅读
-
机器人单笔最大融资!宁王领投银河通用,电池厂商为何集体涌入?
2025-06-2511阅读
-
财富观 | 脑机接口技术进入“元年”,却被吐槽“投资不起”
2025-06-2511阅读
-
水星伴月将限时上演,周五日落后记得抬头看!
2025-06-2511阅读
-
日本“坚韧”号月表着陆失败
2025-06-2511阅读
-
刘劲松等:工业智能体发展现状、关键技术与应用场景研究
2025-06-2511阅读
-
补短强基 掌握创新主动权 江苏加快国产科研仪器自主创新
2025-06-2511阅读
-
飞赛道无人机获奖,如何成为求职“金钥匙”?
2025-06-2511阅读
-
巨型小行星或于2032年撞击月球,并将碎片射向地球威胁到卫星
2025-06-2511阅读

