OpenAI又抢了谷歌风头!AI模型最先拿下IMO金牌的头魁原来是谷歌DeepMind,只是因为内部流程审批慢,被OpenAI抢占先机,占尽风头。那助OpenAI拿下IMO金牌的模型有何特殊之处?它背后的争议为何引发菲尔兹奖得主陶哲轩公开出面发声?
谁曾想,OpenAI又抢尽了谷歌的风头!
爆料称,谷歌DeepMind的AI模型早在本周五,也就是两天前,便拿下了IMO金牌。
但由于内部审核慢,需等下周一市场部批准后,DeepMind才能官宣具体情况。
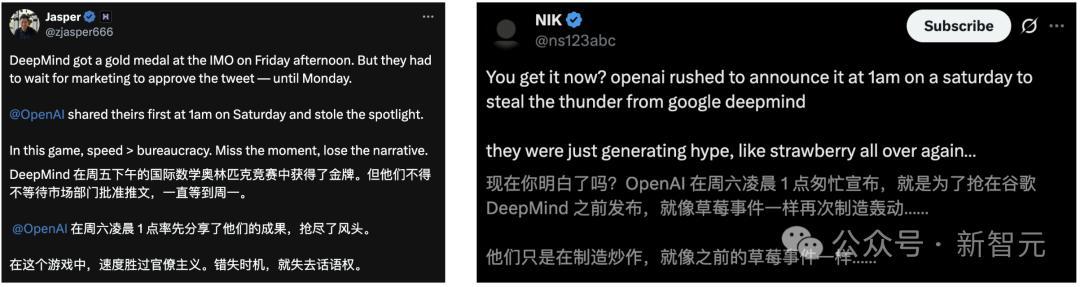
OpenAI瞅中了时机,用全新通用推理模型在IMO刷题后,立即公开了结果。
昨天,全网几乎都被OpenAI拿下IMO金牌刷屏了。自家研究员纷纷现身,宣传OpenAI神秘模型的强大。
如今看来,这一切都是有预谋的。
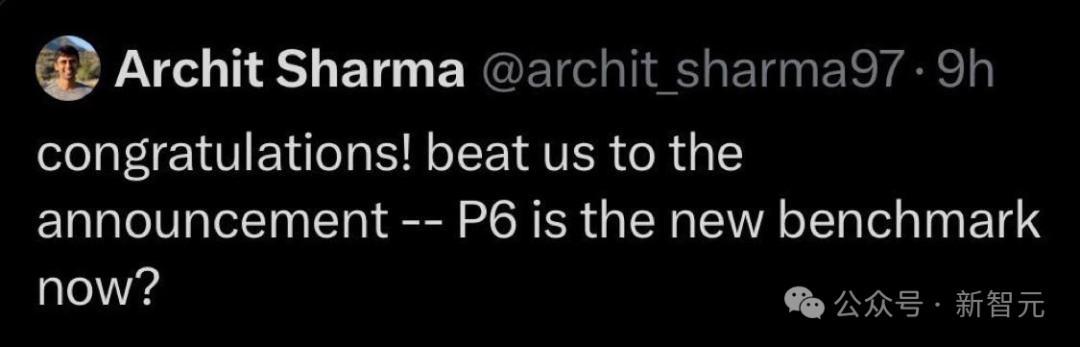
谷歌DeepMind研究员Archit Sharma调侃道,「恭喜!居然比我们先官宣了——现在P6是新标杆了吗」?

OpenAI抢夺IMO金牌
GPT-5即将诞生
为什么通用推理模型拿下IMO金牌,会受到热烈关注?
简而言之,OpenAI这次的通用推理模型在「通用强化学习和测试时计算扩展方面开辟了新天地。」
这次的通用推理模型有啥不同之处?

OpenAI推理研究员Noam Brown指出,这个模型并非专门为国际数学奥林匹克竞赛(IMO)设计。
它是一个融合了全新实验性通用技术的推理LLM,使其在难以验证的任务上表现得更好。
IMO问题正是这一挑战的完美体现:证明过程长达数页,专家需要花费数小时来评分。
相比之下,AIME的答案只是一个0到999之间的整数。
与过去的基准相比,IMO问题需要更高层次的持续创造性思维。
这次的通用推理模型,在推理时间跨度上实现了逐步进步:从GSM8K(顶尖人类约 0.1 分钟)→ MATH基准(约1分钟)→ AIME(约10分钟)→ IMO(约100 分钟)。
「重要的是,它的思考效率也更高。而且在测试时计算能力和效率方面还有很大的提升空间。」

其次,IMO的参赛作品是难以验证的多页证明。
在这方面的进展需要超越明确、可验证奖励的强化学习范式。
通过这样做,就可以获得一个能够像人类数学家一样,构建复杂且无懈可击论证的模型。

https://github.com/aw31/openai-imo-2025-proofs/blob/main/problem_1.txt
这项成果到底意味着什么?
Noam Brown给出了答案:

可能因为这次IMO事件,奥特曼也出来公开发声。
他称,OpenAI拿下IMO金牌这事,需要强调的是,「这是一个LLM在做数学题,而不是一个特定的形式化数学系统这是朝着AGI迈进的主要部分。」

其实,奥特曼之所以这么「积极主动」,也不难发现是在为GPT-5发布提前铺路呢!
当下这个节点对OpenAI非常重要,令人期待的GPT-5即将面世。
他们估计想在这个重要节点上,利用OpenAI拿下IMO金牌这事,为GPT-5来波神助攻。
但奥特曼也稍显谨慎,调低各位对GPT-5的预期。
他指出,GPT-5是一个实验性模型,用了一些将在未来模型中使用的新研究技术。
「在数月内,不会发布具备IMO金牌水平能力的模型。」
陶哲轩点评IMO
针对IMO金牌得主背后争议,数学大佬陶哲轩也公开表达了自己的看法。
「不会评论任何未预先公开测试方法的AI竞赛成绩报告。」
陶哲轩简明扼要,在缺乏受控测试环境的情况下,AI的数学能力难以准确评估。
他指出,很多人对AI有个误解,就是把它的能力看成是「行」或「不行」两个极端。
但实际上,它的能力是一个巨大的范围。你给它提供的计算资源、给它的指令有多好,以及你要求它如何输出结果,都会导致最终效果产生天壤之别。

以人类竞赛举个栗子: 在刚结束的IMO竞赛中,各国派出六名高中生选手组成的团队(由职业数学家担任领队)。
两天赛程中,每位选手每天用四个半小时独立解答三道难题,仅限纸笔演算。
期间选手严禁交流(包括与领队),仅可向监考询问题目表述问题。领队仅在评分环节向评审委员会申诉,不直接参与解题。
都知道,IMO被视为衡量中学生数学能力的金标准:金牌线今年定为35/42分(即完美解答五题),完整解出一题即可获「荣誉提名」。
但若改变竞赛形式,难度将发生剧变!

考虑一下如果我们以其他方式改变奥林匹克竞赛的形式,其难度水平会发生什么变化?
比如,给学生几天时间来完成每道题,而不是三个题目只给四个半小时。
在考试开始前,团队负责人会将问题改写成学生更容易理解的格式。
学生可以无限使用计算器、计算机代数软件包、形式化证明助手、教科书或上网搜索。
领队让六人团队同时处理同一个问题,相互交流各自的部分进展和遇到的死胡同。
在此期间,队长会引导学生采用更有利的方法,并在某个学生花费过多时间在他们知道不太可能成功的方向时进行干预。
提交阶段,每位队员提交解答,但队长只选出「最佳」解答递交竞赛,其余的都弃之不用。
如果团队中的学生都未能获得令人满意的解决方案,团队负责人将不会提交任何解决方案,并且会悄然退出比赛,而他们的参与也永远不会被记录。
这些情境下,答案仍「技术性」源自学生之手。
这也说明,竞赛形式的改变能使原本铜牌线下的团队跃升至金牌水平。
「这警示我们,在缺乏统一测试标准的情况下,贸然对比不同AI模型(或AI与人类选手)的IMO表现如同比较苹果与橙子,没有对比意义可言,」陶哲轩指出。
免责声明:本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其内容真实性、完整性不作任何保证或承诺。由用户投稿,经过编辑审核收录,不代表头部财经观点和立场。
证券投资市场有风险,投资需谨慎!请勿添加文章的手机号码、公众号等信息,谨防上当受骗!如若本网有任何内容侵犯您的权益,请及时联系我们。
相关文章
-
AI 对齐了人的价值观,也学会了欺骗丨晚点周末
2025-07-2011阅读
-
谁能“扶起”智界汽车
2025-07-2011阅读
-
马斯克承认曾抵制人工智能,如今全力投入
2025-07-2011阅读
-
广汽华为联合 AI 解决方案入选国际电联全球标杆案例
2025-07-2011阅读
-
鸿蒙智行智界 S7 轿车明日开启 OTA 升级招募 / 推送
2025-07-2011阅读
-
广西汽车、文旅等多个重点领域人工智能专项赛事陆续举办
2025-07-2011阅读
-
国际低空经济博览会“未展先飞”,功能各异的无人机在公园“炫技”
2025-07-2011阅读
-
Bigscreen 联合《VRChat》推出 Beyond 2e 头显售 1269 美元
2025-07-2011阅读
-
9051万元!优必选拿下人形机器人企业采购最高金额订单
2025-07-2011阅读
-
发挥国际数据港优势,香港人工智能×数据蓬勃发展
2025-07-2011阅读

