
还记得半年前 DeepSeek 横空出世时的震撼吗?那个用不到 OpenAI 1/20 的成本就训练出顶级模型的神话,不仅让整个硅谷为之侧目,更是给国内的 AI 创业公司上了生动的一课——原来,大模型可以这样玩。
DeepSeek 冲击波下的转型之路
对于被称为AI 六小龙的 MINIMAX 来说,DeepSeek 的出现无异于一记当头棒喝。过去的剧本突然就讲不下去了:疯狂烧钱买算力,追着 OpenAI 的脚步跑,今天发个大模型,明天搞个视频生成...看起来很忙,但总感觉在原地打转。
投资人开始问:既然 DeepSeek 能用这么少的钱做出这么好的效果,你们之前烧的那些钱都去哪了?用户开始问:既然有免费的 DeepSeek,我为什么还要付费用你们的 API?
但 MINIMAX 的反应出人意料地迅速和果断。他们没有选择继续讲老故事,而是彻底换了剧本:从追逐热点转向硬核技术突破,从商业化优先转向开源优先,从模仿 OpenAI 转向对标 DeepSeek。
实际上,MiniMax 在今年 1 月份就推出了开源模型 Minimax-01,其中包括语言模型和视觉模型,但似乎反向平平。
半年的蛰伏与沉淀后,他们暂停了所有非核心项目,把最优秀的工程师都调到了一个神秘的项目上。
MiniMax-M1:半年磨一剑的技术突破
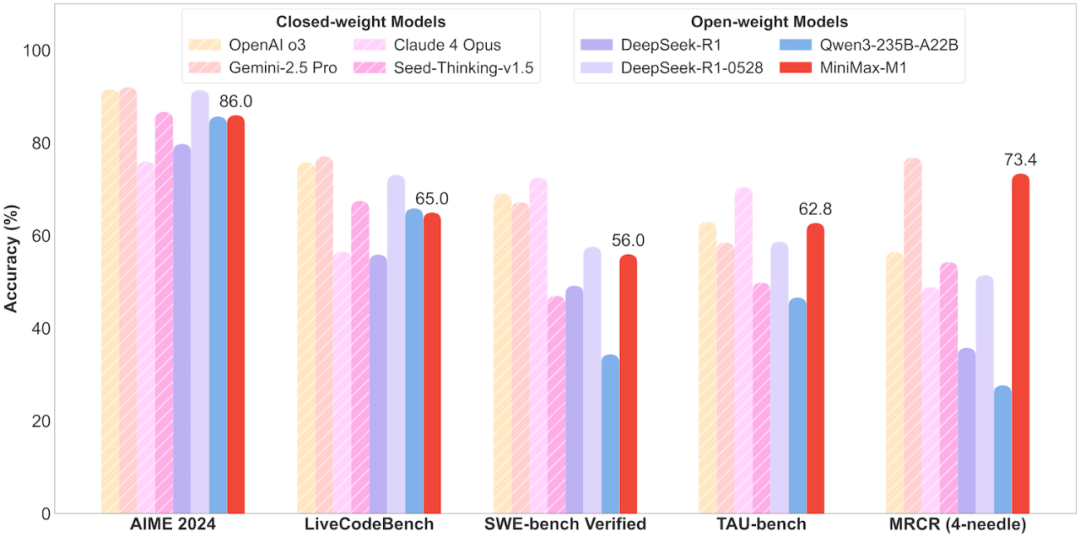
昨天,MINIMAX 终于交出了答卷——MiniMax-M1,他们宣称这是世界上第一个开源的大规模混合架构的推理模型。这不是一个匆忙的应景之作,而是一次深思熟虑的技术革新。
免责声明:本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其内容真实性、完整性不作任何保证或承诺。由用户投稿,经过编辑审核收录,不代表头部财经观点和立场。
证券投资市场有风险,投资需谨慎!请勿添加文章的手机号码、公众号等信息,谨防上当受骗!如若本网有任何内容侵犯您的权益,请及时联系我们。
相关文章
-
跨境创业更简单!首届全球POD生态大会,邀您共享行业红利
2025-06-180阅读
-
罗永浩百度电商直播背后,一场千万人围观的“技术秀”
2025-06-180阅读
-
河南银行业重拳整顿汽车消费金融:利率设限、高佣金终结
2025-06-180阅读
-
巴奴火锅人均消费额走低,收入不及凑凑此前表现,凭什么闯上市?
2025-06-180阅读
-
海底捞22元工作餐背后:餐饮巨头的下沉生存战
2025-06-180阅读
-
免费为企业展销!《梅州市实施“免费展销”工作方案(试行)》印发→
2025-06-180阅读
-
廊洽之约丨好玩好逛好吃!2025年廊坊经洽会精彩纷呈
2025-06-180阅读
-
AGV激光叉车应用现状与发展趋势
2025-06-180阅读
-
宜家深圳宝安商场将于6月19日开业
2025-06-180阅读
-
擦亮紫色花海“金字招牌” “花卉+”激活吃、住、游、购综合消费新动能
2025-06-180阅读

